引言
今天我咬牙开通了 ChatGPT Pro 的订阅。为了最大化这项投资的价值,我计划开启一个新的系列:每天与 ChatGPT 深入探讨一个重要话题,并将这些有见地的对话整理成文,分享给大家。
今天,我选择了一个与 AI 发展密切相关的话题:大语言模型的全面评测方法。这个问题的灵感来自于最近 Grok 3 的发布。在各大模型发布时,我们经常会看到各种评测数据和对比图表,比如下面这张来自 Grok 3 发布会的评测结果:
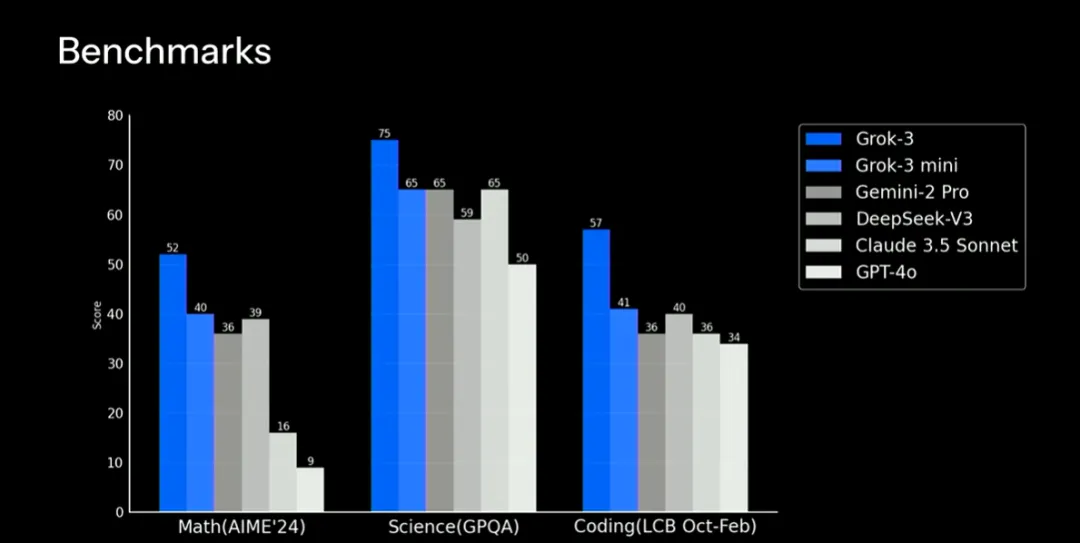
这些评测数据背后究竟有着怎样的评估体系?评测指标是如何设定的?评测的基本原理是什么?更进一步,当我们需要将 AI 技术整合到实际产品中时,应该如何设计一个全面而有效的评测方案?带着这些问题,我让 ChatGPT 帮我进行了深度研究。
对话内容





小记
-
评测方法多样化:现在评测大模型,不仅看它在考试(各种数据集)里答题准不准,还会让人和模型聊聊天(像Chatbot Arena那样),或者让模型之间互相打分,方法更多样了。
-
考察维度更全面:除了看模型聪明不聪明(准确性),还要看它靠不靠谱(安全性、会不会瞎编)、好不好用(流畅性、能不能听懂人话)、省不省钱(计算效率)等等。
-
模型自己当评委:厉害的大模型(比如GPT-4)可以给别的模型打分,这比人来打分快得多,而且打得还挺准,特别适合用来评估聊天机器人。
-
评测推动技术进步:大模型公司都想在评测里拿高分,这就像一场比赛,促使大家不断改进模型,也让用户能选到更好的模型。
-
评测方式不断进步:评测本身也在变得更智能、更实用,会更像真实使用场景,也会更透明,让大家更放心。