开发者通常首先致力于确保智能体正常运行,之后才会关注其速度和成本优化。我们发现开发者们通常会采取以下几种方法:
- 找出延迟的来源
- 改变用户体验(UX)以减少"感知"延迟
- 减少大语言模型的调用次数
- 加速大语言模型的调用
- 并行执行大语言模型的调用
找出延迟的来源
这看似简单,但减少延迟的方法很大程度上取决于你的具体瓶颈所在。延迟是源于单次大型 LLM 调用,还是多次小型调用的累积?在尝试加速之前,你需要诊断清楚这些问题。
LangSmith 是一个非常有用的工具,它能让你全面监控智能体的各个交互环节。你可以追踪智能体每个步骤的延迟,而且我们最近还引入了一个"瀑布"视图,可以轻松识别哪些步骤对整体延迟的贡献最大。
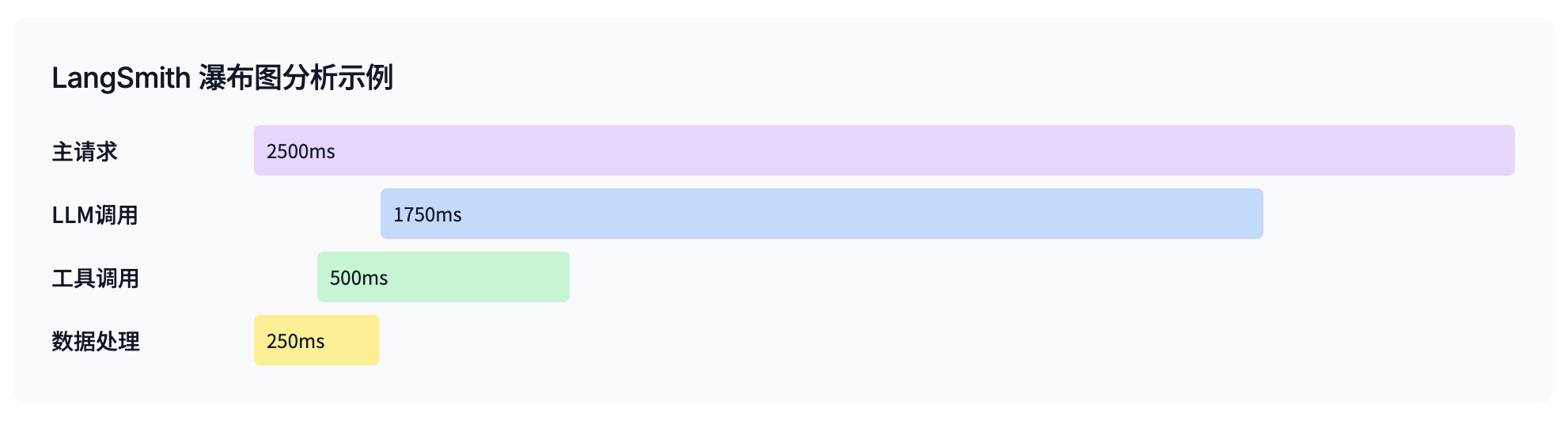
改变用户体验(UX)以减少"感知"延迟
有时,降低延迟最简单的方法……竟然是不减少延迟。
乍一看可能有些违反直觉,但如果我们思考一下延迟为什么重要——通常是因为人们担心智能体运行时间过长,用户会不喜欢使用它。通常,优化智能体的用户体验(UX)可以有效缓解这一问题。我们看到人们主要通过两种方式来实现这一点:
-
流式输出结果。 流式传输对于大多数大语言模型应用程序来说都很常见,如果你还没有这样做,那么绝对应该考虑。它可以向用户传达大语言模型正在工作的信息,并且他们不太可能离开页面。除了流式传输响应令牌(token)之外,你还可以流式传输最终结果以外的其他信息。例如,你可以流式传输智能体正在采取的计划步骤、检索结果或思考令牌(token)。Perplexity 的搜索界面在这方面表现出色。他们发现,通过更改用户界面(UI)来显示这些中间步骤,用户满意度得到了提高——尽管总完成时间保持不变。
-
在后台运行智能体。 让智能体在后台运行。对于我的电子邮件助手,我无法看到电子邮件智能体需要多长时间。这是因为它是由一个事件(一封电子邮件)触发的,我只会在它卡住时收到通知。我向用户隐藏了所有延迟,智能体只是在后台运行。

减少大语言模型的调用次数
并非所有任务都必须通过调用大型语言模型来完成。如果能够采用其他方法,则更优!目前构建的智能体通常结合了大型语言模型调用和代码。这种将代码与大语言模型调用相结合的混合方法是 LangGraph 的指导原则之一,也是 Replit、Uber、LinkedIn 和 Klarna 等公司采用它的核心原因。
我们通常看到的路径是"单次大语言模型调用"→"ReAct 智能体"→"多智能体"→"LangGraph"。

最初,人们通常只调用一次大语言模型;但当他们遇到局限时,就会选择升级为智能体。这还算可以,但当他们尝试给它更多的工具时,他们意识到单个智能体只能支持这么多工具。然后他们转向"多智能体"设置,使用监督者或蜂群架构(即 swarm architecture)。
这样做的问题是,这些架构使用了大量的大语言模型调用。它们在不同智能体之间的通信效率不高。这是设计使然——它们是通用架构,因此没有针对你的用例进行优化。
这时,我们看到人们开始使用 LangGraph。LangGraph 是底层工具,允许你精确地指定这些智能体应该如何相互通信(或者何时仅仅是进行一次大语言模型调用)。通常,这会导致大语言模型调用次数显著减少,从而使智能体更快、更便宜(而且通常更可靠)。
加速大语言模型的调用
我们通常看到开发者通过两种方式来加速大语言模型的调用:
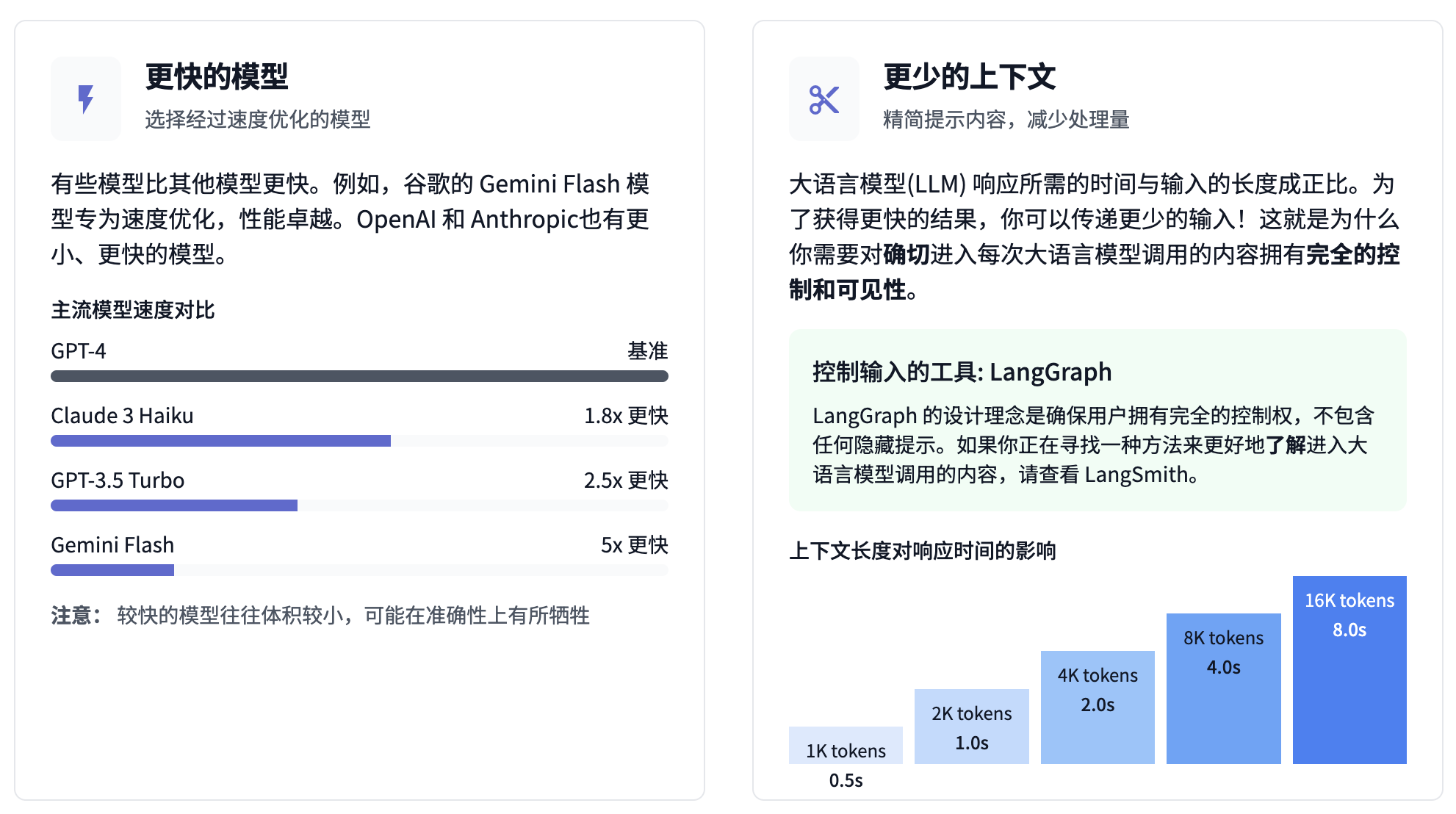
更快的模型。 有些模型比其他模型更快。例如,谷歌的 Gemini Flash 模型专为速度优化,性能卓越。OpenAI 和 Anthropic 也有更小、更快的模型。像 Groq 和 Fireworks 这样的开源模型托管平台也在不断努力使最好的开源模型越来越快。注意:这通常需要权衡,因为较快的模型往往体积较小,可能在准确性上有所牺牲。
更少的上下文。 大语言模型响应所需的时间与输入的长度成正比。为了获得更快的结果,你可以传递更少的输入!这就是为什么你需要对确切进入每次大语言模型调用的内容拥有完全的控制和可见性。如果框架对这些细节进行模糊处理(或难以控制),则可能不太理想。LangGraph 的设计理念恰恰相反,不包含任何隐藏提示,确保用户拥有完全的控制权。如果你正在寻找一种方法来更好地了解进入大语言模型调用的内容,请查看 LangSmith。
并行执行大语言模型的调用
虽然这种方法并不适用于所有场景,但如果适合你的需求,就应当采用。LangGraph 提供开箱即用的并行处理能力,方便用户实现并行计算。你可以考虑在以下情况下这样做:
- 并行执行安全护栏检查和生成
- 并行从多个文档中提取信息
- 并行调用多个模型,然后组合输出

结论
加速你的 AI 智能体最终是在性能、成本和能力之间做出战略性权衡。首先要了解你的具体性能瓶颈,然后根据你的用例有选择地应用这些技术。而且,有时最有效的方法根本不是技术性的——而是重新思考用户如何体验与你的智能体的交互。