《智能体设计模式》中文翻译计划启动
正如《设计模式》曾是软件工程的圣经,这本由谷歌资深工程主管免费分享的《智能体设计模式》,正为火热的 AI 智能体领域带来首套系统性的设计原则与最佳实践。
本书由 Antonio Gulli 撰写、谷歌 Cloud AI 副总裁 Saurabh Tiwary 作序、高盛 CIO Marco Argenti 鼎力推荐,系统性地提炼出 21 个核心智能体设计模式,涵盖从提示链、工具使用到多智能体协作、自我修正等关键技术。
接下来的一个月,我将通过 AI 初次翻译 → AI 交叉评审 → 人工精读优化的方式来翻译这本书,所有翻译内容将持续更新到开源项目:github.com/ginobefun/agentic-design-patterns-cn
已翻译章节:
并行模式精华概览
并行模式通过同时执行多个独立任务来提升智能体系统的效率和响应速度,将原本需要串行等待的操作转变为并发执行,是优化复杂智能体工作流性能的关键技术。这里为大家梳理几个关键要点:
1. 核心理念:从顺序到并发
并行模式的核心在于识别工作流中互不依赖的环节,并将它们并发执行,从而大幅缩短总体执行时间。
- 顺序执行的局限:传统的线性工作流让每个任务等待前一个任务完成才开始执行,在涉及多个外部 I/O 操作 (如 API 调用、数据库查询) 时,总耗时会是各个任务耗时的累加,导致系统响应缓慢、效率低下。
- 并行模式的价值:通过同时启动多个独立任务,在等待外部资源响应的同时执行其他操作,能显著减少总等待时间。例如研究智能体可以同时搜索多个数据源,而非逐个查询。
2. 典型应用场景
并行模式在七大场景中展现出显著优势:
- 信息收集和研究:同时从新闻、股票数据、社交媒体、公司数据库等多个来源收集信息,快速获得全面视图。
- 数据处理和分析:并行进行情感分析、关键词提取、分类、紧急问题识别等多维度分析,提供多角度洞察。
- 多 API 或工具交互:旅行规划时同时检查航班、酒店、活动、餐厅,快速制定完整行程。
- 多组件内容生成:营销邮件创作时并行生成主题、正文、图片、按钮文案,高效完成内容制作。
- 验证和核实:同时检查邮件格式、电话号码、地址、不当内容,快速完成多重验证。
- 多模态处理:同时分析文本情感和图像内容,快速整合不同模态的信息。
- A/B 测试或方案生成:并行生成多个文案版本,快速比较并选出最优方案。
3. 实现框架与特点
- LangChain/LCEL:使用
RunnableParallel将多个可运行组件打包成字典或列表,框架会自动并行执行所有组件,然后将结果传递给下一步。 - LangGraph:通过图的拓扑结构实现并行,从一个公共节点同时触发多个无依赖关系的节点,各路径独立运行后在汇聚点合并。
- Google ADK:使用
ParallelAgent协调多个子智能体的并发执行,配合SequentialAgent可构建「先并行再汇总」的完整流程。
4. 使用时机:适用场景
当系统满足以下任一条件时,应考虑使用并行模式:
- 工作流包含多个相互独立、无依赖关系的子任务;
- 需要调用多个外部 API 或服务来获取不同类型的数据;
- 要对同一输入进行多种不同的处理或分析;
- 总执行时间主要消耗在等待外部资源响应上;
- 需要生成多个版本的输出以供比较和选择。
以下为原书第三章并行模式的内容,原文链接:Chapter 3: Parallelization,译者:@Gino
并行模式概述
在前面的章节中,我们探讨了用于顺序工作流的提示链以及用于智能决策的路由模式。虽然这些模式很重要,但许多复杂的智能体任务需要 同时 执行多个子任务,而非一个接一个地执行。这时 并行模式 就变得至关重要。
并行模式涉及同时执行多个组件,例如大语言模型调用、工具使用,甚至整个子智能体(见图 1)。与等待一个步骤完成后再开始下一个步骤不同,并行执行允许独立任务同时运行,这大大缩短了那些可以分解为相互独立部分的任务的总执行时间。
考虑实现一个研究主题并汇总结论的智能体。按顺序执行时可能会是这样:
- 搜索来源 A。
- 总结来源 A。
- 搜索来源 B。
- 总结来源 B。
- 整合总结 A 和 总结 B 中的内容,生成一个最终答案。
如果使用并行模式则可以优化为:
- 同时 搜索来源 A 和来源 B。
- 两次搜索完成后,同时对来源 A 和来源 B 进行总结。
- 整合总结 A 和 总结 B 中的内容,生成一个最终答案。这一步通常按顺序进行,需要等待前面并行步骤全部完成。
并行模式的核心在于找出工作流中互不依赖的环节,并将它们并行执行。在处理外部服务(如 API 或数据库)时,这种做法特别有效,因为可以同时发起多个请求,从而减少总体等待时间。
实现并行化通常需要使用支持异步执行、多线程或多进程的框架。现代智能体框架原生都能支持异步操作,帮助你方便地定义并同时运行多个步骤。
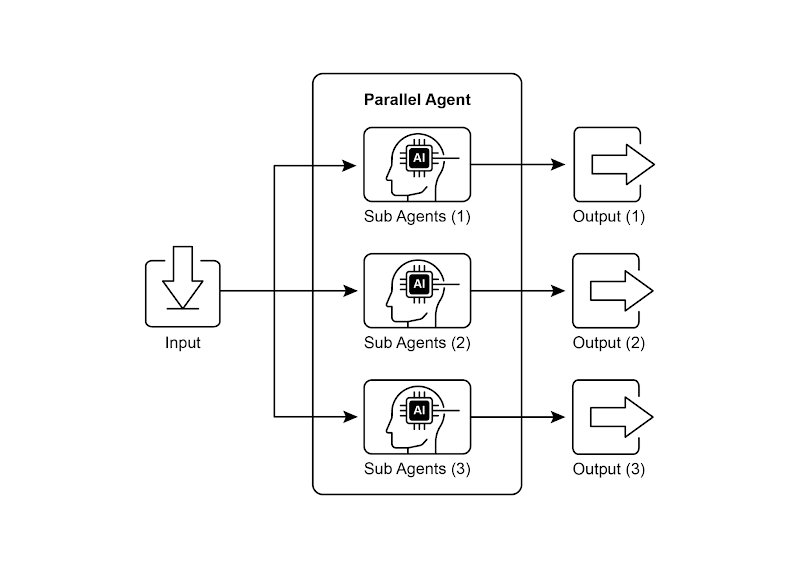
图 1:使用子智能体进行并行化的示例
LangChain、LangGraph 和 Google ADK 等框架都提供了并行执行机制。
在 LangChain 表达式语言(LCEL)中,可以使用 | 等运算符组合可运行对象,并通过设计具有并发分支的链或图结构来实现并行执行。而 LangGraph 则利用图结构,允许从状态转换中执行多个节点,从而在工作流中实现并行分支。
Google ADK 也提供了强大的原生机制来促进和管理智能体的并行执行,显著提升了复杂多智能体系统的效率和可扩展性。ADK 框架的这一内在能力使开发者能够设计并实现让多个智能体并发运行(而非顺序执行)的解决方案。
并行模式对于提升智能体系统的效率和响应速度至关重要,特别是在需要执行多个独立查询、计算或与外部服务交互的场景中。它是优化复杂智能体工作流性能的关键技术。
实际应用场景
并行模式可以在各种场景中使用以提升智能体性能:
1. 信息收集和研究:
一个经典的用例就是同时从多个来源收集信息。
- 用例: 研究某个公司的智能体。
- 并行执行任务: 同时搜索新闻、拉取股票数据、监测社交媒体上的提及,并查询公司数据库。
- 好处: 比逐项查找更快获得全面信息。
2. 数据处理和分析:
使用不同的分析方法或并行处理不同的数据段。
- 用例: 分析客户反馈的智能体。
- 并行处理任务: 在一批反馈中同时进行情感分析、关键词提取、分类,并识别需要优先处理的紧急问题。
- 好处: 快速提供多角度的分析。
3. 多个 API 或工具交互:
调用多个独立的 API 或工具,以获取不同类别的信息或完成不同的任务。
- 用例: 旅行规划智能体。
- 并行处理任务: 同时检查航班价格、搜索酒店、了解当地活动,并找到推荐的餐厅。
- 好处: 更快速地制定出完整的旅行行程。
4. 多组件内容生成:
并行生成复杂作品的各个部分。
- 用例: 撰写营销邮件的智能体。
- 并行处理任务: 同时生成邮件主题、撰写正文、查找相关图片,并设计具有号召性的按钮文案。
- 好处: 更高效地生成电子邮件内容。
5. 验证和核实:
并行执行多个彼此独立的检查或验证。
- 用例: 验证用户输入的智能体。
- 并行执行任务: 同时检查邮件格式、验证电话号码、在数据库中核对地址,并检查是否有不当内容。
- 好处: 能够更快地反馈输入是否有效。
6. 多模态处理:
同时对同一输入的不同模态(文本、图像、音频)数据进行处理。
- 用例: 分析包含文本和图像的社交媒体帖子的智能体。
- 并行执行任务: 同时分析文本的情感和关键词,以及分析图像中的对象和场景描述。
- 好处: 能更快地综合来自不同模态的信息与洞见。
7. A/B 测试或多种方案生成:
并行生成多个响应或输出版本,然后从中挑选最佳的一种。
- 用例: 生成多个创意文案的智能体。
- 并行执行任务: 同时使用稍微不同的提示或模型为同一篇文章生成三条各具风格的标题。
- 好处: 可以快速比较各个方案并选出最优者。
并行模式是智能体设计中的一项重要优化技术。通过对独立任务进行并发执行,开发者可以构建更高效、更具响应性的应用程序。
实战示例:使用 LangChain
在 LangChain 框架中,通过 LangChain 的表达式语言(LCEL)可以实现并行执行。常见做法是把多个可运行组件组织成字典或列表,并把这个集合作为输入传给链中的下一个组件。LCEL 执行器会并行执行集合中的各个可运行项。
在 LangGraph 中,这一原则体现在图的拓扑结构上。通过从一个公共节点同时触发多个没有直接顺序依赖的节点,就能形成并行工作流。这些并行路径各自独立运行,之后在图中的某个汇聚点合并结果。
以下示例展示了如何使用 LangChain 框架构建并行处理流程:针对同一个用户查询,工作流同时启动两个互不依赖的操作,然后将它们各自的输出合并为一个最终结果。
要实现此功能,首先需要安装必要的 Python 包(如 langchain、langchain-community 及 langchain-openai 等模型提供库)。同时需要在本地环境中配置所选语言模型的有效 API 密钥,以便进行身份验证。
import os
import asyncio
from typing import Optional
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import Runnable, RunnableParallel, RunnablePassthrough
# Colab 代码链接:https://colab.research.google.com/drive/1uK1r9p-5sdX0ffMjAi_dbIkaMedb1sTj
# 安装依赖
# pip install langchain langchain-community langchain-openai langgraph
# For better security, load environment variables from a .env file
# 为了更好的安全性,建议从 .env 文件加载环境变量
from dotenv import load_dotenv
load_dotenv()
# --- Configuration ---
# Ensure your API key environment variable is set (e.g., OPENAI_API_KEY)
# 确保你的 API 密钥环境变量已设置 (如 OPENAI_API_KEY)
try:
llm: Optional[ChatOpenAI] = ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
if llm:
print(f"Language model initialized: {llm.model_name}")
except Exception as e:
print(f"Error initializing language model: {e}")
llm = None
# --- Define Independent Chains ---
# These three chains represent distinct tasks that can be executed in parallel.
# --- 定义独立的链 ---
# 这三条链代表彼此独立、可同时执行的任务。
summarize_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "Summarize the following topic concisely:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
questions_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "Generate three interesting questions about the following topic:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
terms_chain: Runnable = (
ChatPromptTemplate.from_messages([
("system", "Identify 5-10 key terms from the following topic, separated by commas:"),
("user", "{topic}")
])
| llm
| StrOutputParser()
)
# --- Build the Parallel + Synthesis Chain ---
# 1. Define the block of tasks to run in parallel. The results of these,
# along with the original topic, will be fed into the next step.
# --- 定义要并行执行的任务块。这些结果以及原始内容将作为输入传递给下一步。
map_chain = RunnableParallel(
{
"summary": summarize_chain,
"questions": questions_chain,
"key_terms": terms_chain,
"topic": RunnablePassthrough(), # Pass the original topic through
}
)
# 2. Define the final synthesis prompt which will combine the parallel results.
# --- 定义最终的综合提示,将并行结果合并。
synthesis_prompt = ChatPromptTemplate.from_messages([
("system", """Based on the following information:
Summary: {summary}
Related Questions: {questions}
Key Terms: {key_terms}
Synthesize a comprehensive answer."""),
("user", "Original topic: {topic}")
])
# 3. Construct the full chain by piping the parallel results directly
# into the synthesis prompt, followed by the LLM and output parser.
# --- 通过将并行结果直接传递给综合提示,然后是语言模型和输出解析器,构建完整的链。
full_parallel_chain = map_chain | synthesis_prompt | llm | StrOutputParser()
# --- Run the Chain ---
# --- 运行链 ---
async def run_parallel_example(topic: str) -> None:
"""
Asynchronously invokes the parallel processing chain with a specific topic
and prints the synthesized result.
Args:
topic: The input topic to be processed by the LangChain chains.
"""
if not llm:
print("LLM not initialized. Cannot run example.")
return
print(f"\n--- Running Parallel LangChain Example for Topic: '{topic}' ---")
try:
# The input to `ainvoke` is the single 'topic' string, which is
# then passed to each runnable in the `map_chain`.
response = await full_parallel_chain.ainvoke(topic)
print("\n--- Final Response ---")
print(response)
except Exception as e:
print(f"\nAn error occurred during chain execution: {e}")
if __name__ == "__main__":
test_topic = "The history of space exploration"
# In Python 3.7+, asyncio.run is the standard way to run an async function.
asyncio.run(run_parallel_example(test_topic))运行输出(译者添加):
Language model initialized: gpt-4o-mini
--- Running Parallel LangChain Example for Topic: 'The history of space exploration' ---
--- Final Response ---
The history of space exploration is a fascinating narrative marked by human curiosity, technological advancement, and international cooperation. It began in the mid-20th century, with the launch of the Soviet satellite Sputnik 1 in 1957, which signified the dawn of the Space Age. This event triggered a series of significant milestones that would shape our understanding of the cosmos.
In 1961, the Soviet space program successfully launched Yuri Gagarin, the first human to journey into space, further igniting the Space Race between the United States and the Soviet Union. This fierce competition led to rapid advancements in technology and culminated with the U.S. Apollo program, which achieved the historic Moon landing in 1969. The success of Apollo 11 not only demonstrated human capability but also inspired generations to look to the stars.
Throughout the 1970s and 1980s, space exploration expanded to include missions to Mars, the launch of revolutionary space telescopes like the Hubble Space Telescope, and the development of the Space Shuttle program. These initiatives allowed for more extended missions and the ability to deploy and service satellites, enhancing our understanding of the universe and our place within it.
The late 1990s saw the launch of the International Space Station (ISS), a landmark achievement in international cooperation in space research. The ISS has become a platform for collaboration among multiple space agencies, including NASA, Roscosmos, ESA, JAXA, and others, allowing scientists from around the world to work together in the unique environment of space.
In recent years, technological advancements, particularly in the realm of reusable rockets, have reshaped the goals and capabilities of space exploration. Companies such as SpaceX and Blue Origin have pioneered private spaceflight initiatives, driving costs down and making space more accessible than ever. This shift has reignited interest in missions targeting Mars, the Moon, and beyond, with plans for crewed missions to Mars on the horizon.
The Space Race has also had lasting effects on international cooperation in contemporary space exploration. The competitive spirit of the Cold War era has evolved into a collaborative approach, exemplified by the ISS and joint missions like the Mars rover endeavors, where multiple countries contribute resources and expertise to achieve common goals.
However, the entrance of private companies into the space exploration sector raises various ethical considerations and potential implications. These include questions about the commercialization of space, the prioritization of profit over scientific research, and concerns about space debris and environmental impacts. As private entities take on larger roles in exploration, the dynamics of scientific research and exploration beyond Earth's atmosphere may shift, necessitating new frameworks for governance and collaboration.
In summary, the history of space exploration is a rich tapestry woven from human ingenuity and cooperation. It reflects our quest to understand the universe, marked by milestones that highlight both our achievements and the challenges that lie ahead. As we move into a new era of exploration, the interplay between public and private initiatives will shape the future of our endeavors among the stars.上述 Python 示例实现了一个基于 LangChain 的应用,通过并发执行来更高效地处理指定话题。需要说明的是,asyncio 实现的是并发(Concurrency),不是多线程或多核的真正并行(Parallelism)。它在单个线程中运行,通过事件循环在任务等待(如等待网络响应)时切换执行,从而让多个任务看起来同时执行。但底层代码仍在同一线程上运行,这是受 Python 全局解释器锁(GIL)的限制。
代码从 langchain_openai 和 langchain_core 导入了关键模块,包含语言模型、提示模板、输出解析器和可运行组件。接着尝试初始化一个
ChatOpenAI 实例,指定使用 gpt-4o-mini 模型,并设置了控制创造力的温度值,初始化时用 try-except 来保证健壮性。随后定义了三条相互独立的 LangChain 链,每条链负责对输入主题执行不同任务:第一条链用来简洁地总结主题,采用系统消息和包含主题占位符的用户消息;第二条链生成与主题相关的三个有趣问题;第三条链则从主题中识别 5 到 10 个关键术语,要求用逗号分隔。每条链都由为该任务定制的 ChatPromptTemplate、已初始化的语言模型和用于把输出格式化为字符串的 StrOutputParser 组成。
随后构建了一个 RunnableParallel块,把这三条链打包在一起以便同时运行。这个运行单元还包含一个 RunnablePassthrough,确保原始输入的主题可以在后续步骤中使用。
接着为最后的汇总步骤定义了一个独立的 ChatPromptTemplate,使用摘要、问题、关键术语和原始主题作为输入来生成完整的答案。这个名为 full_parallel_chain 的端到端处理链,是通过 map_chain 连接到汇总提示,再接语言模型和输出解析器来构建的。
示例中提供了一个异步函数 run_parallel_example,用来演示如何调用这个 full_parallel_chain,该函数接收主题作为输入并通过 invoke 运行异步链。
最后,通过标准的 Python if __name__ == "__main__": 代码块演示如何用 asyncio.run 管理异步执行,来启动 run_parallel_example 方法,其中主题为「航天探索史」。
本质上,这段代码构建了一个工作流:针对某个主题,使用大语言模型同时进行摘要、提问和术语等多个调用,随后由一次最终的请求把这些输出整合在一起。该示例说明了在使用 LangChain 的智能体工作流中通过并行执行来提高效率的核心思想。
实战示例:使用 Google ADK
现在通过 Google ADK 框架中的具体示例来说明这些概念。我们将展示 ADK 的基本组件(如 ParallelAgent 和 SequentialAgent)来构建智能体流程,从而通过并行执行提高效率。
# Part of agent.py --> Follow https://google.github.io/adk-docs/get-started/quickstart/ to learn the setup
# --- 1. Define Researcher Sub-Agents (to run in parallel) ---
# --- 定义研究员子智能体(并行执行) ---
# Researcher 1: Renewable Energy
# 研究员 1:可再生能源
researcher_agent_1 = LlmAgent(
name="RenewableEnergyResearcher",
model=GEMINI_MODEL,
instruction="""You are an AI Research Assistant specializing in energy.
Research the latest advancements in 'renewable energy sources'.
Use the Google Search tool provided.
Summarize your key findings concisely (1-2 sentences).
Output *only* the summary.
""",
description="Researches renewable energy sources.",
tools=[google_search],
# Store result in state for the merger agent
output_key="renewable_energy_result"
)
# Researcher 2: Electric Vehicles
# 研究员 2:电动汽车
researcher_agent_2 = LlmAgent(
name="EVResearcher",
model=GEMINI_MODEL,
instruction="""You are an AI Research Assistant specializing in transportation.
Research the latest developments in 'electric vehicle technology'.
Use the Google Search tool provided.
Summarize your key findings concisely (1-2 sentences).
Output *only* the summary.
""",
description="Researches electric vehicle technology.",
tools=[google_search],
# Store result in state for the merger agent
output_key="ev_technology_result"
)
# Researcher 3: Carbon Capture
# 研究员 3:碳捕获
researcher_agent_3 = LlmAgent(
name="CarbonCaptureResearcher",
model=GEMINI_MODEL,
instruction="""You are an AI Research Assistant specializing in climate solutions.
Research the current state of 'carbon capture methods'.
Use the Google Search tool provided.
Summarize your key findings concisely (1-2 sentences).
Output *only* the summary.
""",
description="Researches carbon capture methods.",
tools=[google_search],
# Store result in state for the merger agent
output_key="carbon_capture_result"
)
# --- 2. Create the ParallelAgent (Runs researchers concurrently) ---
# This agent orchestrates the concurrent execution of the researchers.
# It finishes once all researchers have completed and stored their results in state.
# --- 2. 创建 ParallelAgent(并行运行多个研究员子智能体) ---
# 该智能体协调多个研究员子智能体的并发执行。
# 所有研究员完成工作并将结果写入状态后,流程即结束。
parallel_research_agent = ParallelAgent(
name="ParallelWebResearchAgent",
sub_agents=[researcher_agent_1, researcher_agent_2, researcher_agent_3],
description="Runs multiple research agents in parallel to gather information."
)
# --- 3. Define the Merger Agent (Runs *after* the parallel agents) ---
# This agent takes the results stored in the session state by the parallel agents
# and synthesizes them into a single, structured response with attributions.
# --- 3. 定义合并智能体(在并行研究员子智能体之后运行) ---
# 该智能体使用并行运行的子智能体已保存在会话状态中的结果,
# 将这些内容整合并归纳为一份结构化的响应,并在相应部分标注出处。
merger_agent = LlmAgent(
name="SynthesisAgent",
model=GEMINI_MODEL, # Or potentially a more powerful model if needed for synthesis
instruction="""You are an AI Assistant responsible for combining research findings into a structured report.
Your primary task is to synthesize the following research summaries, clearly attributing findings to their source areas. Structure your response using headings for each topic. Ensure the report is coherent and integrates the key points smoothly.
**Crucially: Your entire response MUST be grounded *exclusively* on the information provided in the 'Input Summaries' below. Do NOT add any external knowledge, facts, or details not present in these specific summaries.**
**Input Summaries:**
* **Renewable Energy:**
{renewable_energy_result}
* **Electric Vehicles:**
{ev_technology_result}
* **Carbon Capture:**
{carbon_capture_result}
**Output Format:**
## Summary of Recent Sustainable Technology Advancements
### Renewable Energy Findings
(Based on RenewableEnergyResearcher's findings)
[Synthesize and elaborate *only* on the renewable energy input summary provided above.]
### Electric Vehicle Findings
(Based on EVResearcher's findings)
[Synthesize and elaborate *only* on the EV input summary provided above.]
### Carbon Capture Findings
(Based on CarbonCaptureResearcher's findings)
[Synthesize and elaborate *only* on the carbon capture input summary provided above.]
### Overall Conclusion
[Provide a brief (1-2 sentence) concluding statement that connects *only* the findings presented above.]
Output *only* the structured report following this format. Do not include introductory or concluding phrases outside this structure, and strictly adhere to using only the provided input summary content.
""",
description="Combines research findings from parallel agents into a structured, cited report, strictly grounded on provided inputs.",
# No tools needed for merging
# No output_key needed here, as its direct response is the final output of the sequence
)
# --- 4. Create the SequentialAgent (Orchestrates the overall flow) ---
# This is the main agent that will be run. It first executes the ParallelAgent
# to populate the state, and then executes the MergerAgent to produce the final output.
# --- 4. 创建 SequentialAgent(协调整个流程) ---
# 这是将被运行的主智能体。它先执行 ParallelAgent 来填充状态,
# 然后执行 MergerAgent 来生成最终输出。
sequential_pipeline_agent = SequentialAgent(
name="ResearchAndSynthesisPipeline",
# Run parallel research first, then merge
sub_agents=[parallel_research_agent, merger_agent],
description="Coordinates parallel research and synthesizes the results."
)
root_agent = sequential_pipeline_agent该代码建立了一个多智能体系统,用于收集与整合可持续技术进展的资料。系统包含三个子智能体担任不同的研究员:ResearcherAgent_1 聚焦可再生能源,ResearcherAgent_2 研究电动汽车技术,ResearcherAgent_3 调查碳捕集技术。每个研究员子智能体都配置为使用 GEMINI_MODEL 和 google_search 工具,并要求使用一到两句话总结研究结果,随后通过 output_key 将这些总结内容保存到会话状态中。
然后创建了一个名为 ParallelWebResearchAgent 的并行智能体,用于同时运行这三个研究员子智能体。这样可以并行开展研究,节省时间。只有当所有子智能体(研究员)都完成并将结果写入状态后,并行智能体才算执行结束。
接下来,定义了一个 MergerAgent(也是 LlmAgent)来综合研究结果。该智能体将并行研究员子智能体存储在会话状态中的总结内容作为输入。其指令强调输出必须严格基于所提供的总结内容,禁止添加外部知识。
MergerAgent 旨在将合并的发现结构化为报告,每个主题都有标题和简要的结论。
最后,创建了一个名为 ResearchAndSynthesisPipeline 的顺序型智能体来协调整个工作流。作为主要控制器,该主智能体首先执行 ParallelAgent 来进行研究。ParallelAgent 完成后,SequentialAgent 会执行 MergerAgent 来综合收集的信息。sequential_pipeline_agent 被设置为 root_agent,代表运行该多智能体系统的入口。整个流程的设计目标是并行从多个来源高效收集信息,然后将这些信息合并为一份结构化报告。
要点速览
问题所在: 许多智能体工作流涉及多个必须完成的子任务以实现最终目标。纯粹的顺序执行,即每个任务等待前一个任务完成再执行,通常效率低下且速度缓慢。当任务依赖于外部 I/O 操作(如调用不同的 API 或查询多个数据库)时,这种延迟会成为重大瓶颈。没有并发机制时,总耗时就是各个任务耗时的累加,进而影响系统的性能和响应速度。
解决之道: 并行模式通过同时执行彼此独立的任务,提供了一种标准化的解决方案来缩短整体执行时间。它的做法是识别工作流中不相互依赖的部分,比如某些工具调用或大语言模型请求。像 LangChain 和 Google ADK 这样的智能体框架内置了用于定义和管理并发操作的能力。举例来说,主流程可以启动多个并行的子任务,然后在继续下一步之前等待这些子任务全部完成。相比与顺序执行,这种并行执行能大幅减少总耗时。
经验法则: 当工作流中存在多个相互独立且可并行执行的任务时应采用该模式,例如同时从多个 API 拉取数据、并行处理不同的数据分片,或同时生成多个将来需要合并的内容,从而缩短总体执行时间。
可视化总结:
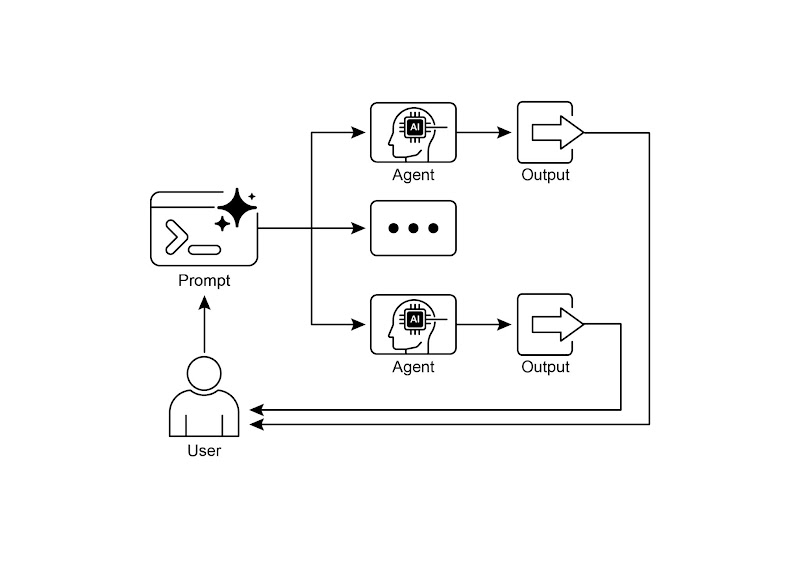
图 2:并行化设计模式
核心要点
以下是本章的关键要点:
- 并行模式是一种将相互独立的任务同时执行,从而缩短总耗时并提高效率的方法。
- 在任务需要等待外部资源(比如调用 API)时,这种方式特别有用。
- 采用并发或并行架构会显著增加复杂性和成本,从而对设计、调试和日志等开发环节带来影响。
- 像 LangChain 和 Google ADK 这样的框架内置了对并行执行的支持,方便定义和管理并行任务。
- 在 LangChain 的表达式语言(LCEL)中,RunnableParallel 是一个核心组件,用于并行执行多个可运行单元。
- Google ADK 可以通过大语言模型驱动的委派机制来实现并行执行,其中协调器智能体中的大语言模型会识别出互相独立的子任务,并将这些任务分派给相应的子智能体去处理,从而并发完成各个子任务。
- 并行模式能有效减少总体耗时,从而提升智能体系统对复杂任务的响应能力。
结语
并行模式是通过并发执行独立子任务来优化计算流程。对于需要多次模型推理或调用外部服务的复杂操作,采用并行执行可以显著降低总体耗时并提高效率。
不同的框架为实现此模式提供了不同的机制。在 LangChain 中,像 RunnableParallel 这样的组件可以用于显式定义和执行多个处理链。相比之下,Google ADK 可以通过多智能体委派机制实现并行化,其中主协调器模型将不同的子任务分配给可以并发执行的专用智能体。
将并行处理与顺序(链式)和条件(路由)控制流结合起来,可以构建既复杂又高效的计算系统,从而更有效地管理各类复杂任务。
参考文献
以下是一些可供深入了解并行模式及其相关概念的推荐阅读资料:
- LangChain 表达式语言文档(并行化):https://python.langchain.com/docs/concepts/lcel/
- Google ADK 文档(多智能体系统):https://google.github.io/adk-docs/agents/multi-agents/
- Python asyncio 文档:https://docs.python.org/3/library/asyncio.html