《智能体设计模式》中文翻译计划启动
正如《设计模式》曾是软件工程的圣经,这本由谷歌资深工程主管免费分享的《智能体设计模式》,正为火热的 AI 智能体领域带来首套系统性的设计原则与最佳实践。
本书由 Antonio Gulli 撰写、谷歌 Cloud AI 副总裁 Saurabh Tiwary 作序、高盛 CIO Marco Argenti 鼎力推荐,系统性地提炼出 21 个核心智能体设计模式,涵盖从提示链、工具使用到多智能体协作、自我修正等关键技术。
接下来的一个月,我将和几位小伙伴通过 AI 初次翻译 → AI 交叉评审 → 人工精读优化的方式来翻译这本书,所有翻译内容将会持续更新到开源项目:github.com/ginobefun/agentic-design-patterns-cn
已翻译章节:
- 00 -《智能体设计模式》前言部分
- 01 -《智能体设计模式》第一章:提示链模式
- 02 -《智能体设计模式》第二章:路由模式
- 03 -《智能体设计模式》第三章:并行模式
- 04 -《智能体设计模式》第四章:反思模式
反思模式精华概览
反思模式让智能体具备自我评估和迭代改进的能力,通过引入反馈循环来不断优化输出质量。智能体不再只是执行任务并产出结果,而是会回过头来审视自己的工作,找出问题并生成更优版本。这里为大家梳理几个关键要点:
1. 核心理念:从一次性输出到迭代优化
反思模式的核心在于建立「执行 → 评估 → 优化 → 迭代」的反馈循环,让智能体具备自我纠错和持续改进的能力。
- 传统模式的局限:基础智能体工作流通常是一次性执行,产出结果后就结束,无法识别和修复自己的错误,导致输出可能不够准确、完整或符合复杂要求。
- 反思模式的价值:通过引入评估和反思环节,智能体可以检查自己的输出是否准确、连贯、完整,并根据反馈意见进行改进,最终产生更高质量、更可靠的结果。
2. 「生产者-评论者」架构
反思模式的关键实现方式是将流程拆分为两个独立角色,通过职责分离提高评判的客观性:
- 生产者智能体(Producer):专注于完成任务的初始执行,负责生成内容、编写代码或制定计划等,产出第一版输出。
- 评论者智能体(Critic):专门评估生产者的输出,以独立视角根据特定标准(事实准确性、代码质量、风格要求等)分析问题并提供结构化反馈。
- 反馈循环:评论者的意见传回给生产者,生产者据此优化内容,如此迭代直到满足质量要求或达到停止条件。
3. 典型应用场景
反思模式在六大场景中展现出显著优势:
- 创意写作和内容生成:对博客文章、营销文案等进行多轮润色,从流畅性、语气、表达清晰度等方面持续改进。
- 代码生成和调试:编写初始代码后运行测试或静态分析,识别错误或低效之处并优化,生成更健壮的代码。
- 复杂问题解决:在多步推理任务中评估每个步骤,发现问题时回退并尝试其他方案,增强分析和解决能力。
- 摘要和信息综合:对比摘要与原文要点,找出遗漏或不准确之处并修订,生成更准确全面的摘要。
- 规划和策略:制定计划后模拟执行或评估可行性,根据评估结果改进调整,制定更有效的计划。
- 对话智能体:回顾对话历史保持上下文连贯,纠正误会并提升回答质量,实现更自然高效的沟通。
4. 实现框架与特点
- LangChain/LCEL:通过构建对话历史和使用不同系统提示来区分「生产者」和「评论者」角色,迭代执行「生成-评审-改进」循环。
- LangGraph:利用图结构和状态管理原生支持反馈循环和条件跳转,实现完整的迭代反思流程。
- Google ADK:使用
SequentialAgent串联生产者和审查者智能体,配合LoopAgent可实现自动化的迭代改进。
5. 使用时机与权衡
当满足以下条件时应考虑使用反思模式,但需注意其成本:
- 适用场景:输出质量、准确性、细节比速度和成本更重要;任务需要高质量内容、准确代码或详细计划;需要更高客观性或专业评估的场景。
- 成本权衡:每次迭代通常需要额外的模型调用,增加延迟和成本;会话历史不断增长会占用更多内存;可能面临超出上下文窗口或 API 限流的风险。
以下为原书第四章反思模式的内容,原文链接:Chapter 4: Reflection,译者:@Gino
反思模式概述
在前面的章节中,我们探讨了智能体的基础模式:用于顺序执行的提示链(Prompt Chaining)、用于动态路径选择的路由(Routing),以及用于并发任务执行的并行模式(Parallelization)。这些模式使智能体能够更高效、更灵活地执行复杂任务。然而,即使工作流设计再精妙,智能体初始输出或计划也未必最优、准确或完整。这正是反思(Reflection)模式发挥作用之处。
反思模式是指智能体评估自己的工作、输出和内部状态,并利用评估结果改进性能和优化响应。这是一种自我纠正或自我改进的形式。通过这种形式,智能体可以根据反馈、内部剖析及与期望标准的比较,来不断地优化输出、调整方法。反思有时也可由独立的智能体来承担,其职责是专门分析初始智能体的输出。
反思模式与简单顺序链或路由模式有着本质区别。前者只是将输出直接传给下一步,或是在不同路径中做出选择;而反思模式则引入了反馈循环。在这种模式下,智能体并非简单地产出结果就结束了。它会回过头来审视自己的输出(或其生成过程),找出潜在的问题和改进空间,并依据这些洞察生成更优的版本,或是修正其后续的行动策略。
这个过程通常包括以下步骤:
- 执行: 智能体执行任务或生成初始版本的输出。
- 评估/剖析: 智能体(通常借助另一个大语言模型调用或一组规则)对上一步的结果进行分析。该过程旨在检查其事实准确性、内容连贯性、风格、完整度、是否遵循指令以及其他相关标准。
- 反思/优化: 根据上一轮的剖析结果,智能体将确定具体的改进方向。这可能涉及几个方面:生成一个更为精炼的输出、为后续步骤调整参数,甚至是修正整体计划。
- 迭代(可选,但很常见): 随后,智能体便会将优化后的输出或调整过的方法付诸执行,并循环往复地进行整个反思过程,直到最终结果令人满意,或满足了预设的停止条件
反思模式的一个关键且高效的实现方式,是将流程拆分为两个独立的逻辑角色:生产者(Producer)和评论者(Critic)。这通常被称为「生成器-评论者」(Generator-Critic)或「生产者-审查者」(Producer-Reviewer)模型。虽然单个智能体也能进行自我反思,但使用两个专用的智能体(或两个具有不同系统提示的独立大语言模型调用)通常能产出更稳健、更客观的结果。
-
生产者智能体: 主要职责是完成任务的初始执行。它完全专注于生成内容,无论是编写代码、起草博客文章还是制定计划。它会接收初始提示,并据此生成输出的第一个版本。
-
评论者智能体: 该智能体的唯一使命就是评估由生产者生成的输出。它会被赋予一套不同的指令,通常还包含一个独特的角色设定(例如「你是一位高级软件工程师」、「你是一位严谨的事实核查员」)。评论者的指令引导它根据特定标准分析生产者的工作,如事实准确性、代码质量、风格要求和完整性,旨在发现问题、提出改进建议并给出结构化的反馈。
这种职责分离非常有效,因为它避免了智能体自我审查时产生的认知偏见。评论者智能体以全新视角审视输出,完全专注于发现错误和改进空间。它的反馈意见随后传回给生产者智能体,生产者据此对内容进行修改和优化。实战部分 LangChain 和 ADK 代码示例都采用了这种双智能体模型:LangChain 使用特定的 reflector_prompt 创建评论者角色,而 ADK 示例明确区分了生产者和审查者两个智能体。
实现反思模式通常需要构建包含反馈循环的智能体工作流。这可以通过在编码实现迭代循环,或使用支持状态管理和根据评估结果进行条件跳转的框架来完成。虽然单步评估和优化可以在 LangChain/LangGraph、ADK 或 Crew.AI 链中实现,但真正的迭代反思通常需要更复杂的编排。
反思模式对于构建能产出高质量结果、应对复杂任务并展现自我意识与适应能力的智能体非常重要。它让智能体不再只是执行指令,而是发展出更成熟的推理与内容生成能力。
需要特别注意反思模式与目标设定和监控(见第 11 章)的联系。目标为智能体的自我评估提供最终基准,监控则跟踪其进度。在许多实际情形中,反思会充当纠偏机制:利用监控反馈分析偏离之处并据此调整策略。这样的协同作用使智能体从单纯执行者变成有目的的、自主适应以实现目标的系统。
此外,当模型能保持对话记忆时,反思模式的有效性显著增强(见第 8 章)。对话历史为评估阶段提供关键上下文,使智能体不仅能孤立评估输出,还能结合先前交互、用户反馈和不断演变的目标进行评估。这使智能体能从过去的评价反馈中学习并避免重复错误。没有记忆,每次反思都是独立事件;有了记忆,反思成为累积性的循环,每个轮次都建立在上一轮基础上,从而实现更智能、更具上下文感知的优化。
实际应用场景
当输出质量、准确性或对复杂约束的遵从性至关重要时,反思模式非常有用:
1. 创意写作和内容生成:
对生成的文本、故事、诗歌或营销文案进行润色和改进。
- 用例: 撰写博客文章的智能体。
- 反思: 先写一篇草稿,再从流畅性、语气和表达清晰度等方面进行检查,随后根据反馈重写草稿。反复进行,直到文章符合质量要求。
- 好处: 产生更精致、更有效的内容。
2. 代码生成和调试:
编写代码、识别错误并修复它们。
- 用例: 编写 Python 函数的智能体。
- 反思: 编写初始代码,运行测试或静态分析,识别错误或低效之处,然后基于这些发现优化代码。
- 好处: 生成更健壮、功能更完整的代码。
3. 复杂问题解决:
在多步推理任务中,对中间步骤或所提出的解决方案进行评估和审查。
- 用例: 解决逻辑推理类谜题的智能体。
- 反思: 提出一个行动步骤,评估该步骤是否有助于推进问题的解决或引入矛盾;如发现问题,则回退并尝试其他步骤。
- 好处: 增强智能体在复杂问题情境中分析和解决问题的能力。
4. 摘要和信息综合:
对摘要进行润色,使其更准确、完整且简明。
- 用例: 总结长文档的智能体。
- 反思: 先生成一份初步摘要,再将其与原文的要点对照,找出遗漏或不准确之处,随后对摘要进行修订,补充缺失信息并提高准确性。
- 好处: 生成更准确、更全面的摘要。
5. 规划和策略:
评估所提计划,找出存在的问题并提出改进建议。
- 用例: 规划一系列行动以实现特定任务的智能体。
- 反思: 制定计划,模拟执行或根据限制评估可行性,然后根据评估结果对计划进行改进与调整。
- 好处: 制定更有效、更符合实际的计划。
6. 对话智能体:
回顾对话中的前几轮交流,以保持上下文连贯、纠正误会并提升回答的质量。
- 用例: 客户支持聊天机器人。
- 反思: 在用户回复后,回顾整个对话和上一次生成的内容,确认信息前后连贯并针对用户的最新输入做出准确回应。
- 好处: 实现更自然、更高效的沟通。
反思模式为智能体系统增加了一层元认知能力,使其能从自己处理过程和输出中学习,从而产生更智能、更可靠、更高质量的结果。
实战示例:使用 LangChain
要实现完整的迭代反思流程,需要具备状态管理和循环执行的机制。虽然诸如 LangGraph 这类基于图的框架,或自定义的过程式代码可以原生支持这些功能,但通过 LCEL(LangChain 表达式语言)的组合语法,就能清晰地演示反思模式的核心原理。
本示例使用 Langchain 库和 OpenAI 的 GPT-4o 模型实现反思循环,迭代生成并优化一个计算阶乘的 Python 函数。流程从任务提示开始,生成初始代码,然后由扮演高级软件工程师角色的智能体提出改进建议并反复迭代,直到确定代码已无可改进或达到最大迭代次数时结束,最终输出完善后的代码。
首先确保已安装必要的库:
pip install langchain langchain-community langchain-openai还需要为选择的语言模型(例如 OpenAI、Google Gemini、Anthropic)设置 API 密钥。
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage, HumanMessage
# Colab 代码链接:https://colab.research.google.com/drive/1xnL6Rky6nsm4iAhomLnUK3kgwSyyYZfb
# 安装依赖
# pip install langchain langchain-community langchain-openai
# --- Configuration ---
# Load environment variables from .env file (for OPENAI_API_KEY)
# 从 .env 文件加载环境变量(如 OPENAI_API_KEY)
load_dotenv()
# Check if the API key is set
# 检查 API 密钥是否设置
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY not found in .env file. Please add it.")
# Initialize the Chat LLM. We use a powerful model like gpt-4o for better reasoning.
# A lower temperature is used for more deterministic and focused outputs.
# 使用 gpt-4o 或其他模型,并设置较低的温度值以获得更稳定的输出
llm = ChatOpenAI(model="gpt-4o", temperature=0.1)
def run_reflection_loop():
"""
Demonstrates a multi-step AI reflection loop to progressively improve a Python function.
展示了通过多步骤反思循环,逐步改进 Python 函数的方法。
"""
# --- The Core Task ---
# --- 核心任务的提示词 ---
task_prompt = """
Your task is to create a Python function named `calculate_factorial`.
This function should do the following:
1. Accept a single integer `n` as input.
2. Calculate its factorial (n!).
3. Include a clear docstring explaining what the function does.
4. Handle edge cases: The factorial of 0 is 1.
5. Handle invalid input: Raise a ValueError if the input is a negative number.
"""
# --- The Reflection Loop ---
# --- 反思循环 ---
max_iterations = 3
current_code = ""
# We will build a conversation history to provide context in each step.
# 构建对话历史,为每一步提供必要的上下文信息。
message_history = [HumanMessage(content=task_prompt)]
for i in range(max_iterations):
print("\n" + "="*25 + f" REFLECTION LOOP: ITERATION {i + 1} " + "="*25)
# --- 1. GENERATE / REFINE STAGE ---
# In the first iteration, it generates. In subsequent iterations, it refines.
# 在第一次迭代时,生成初始代码;在后续迭代时,基于上一步的反馈优化代码。
if i == 0:
print("\n>>> STAGE 1: GENERATING initial code...")
# The first message is just the task prompt.
# 第一次迭代时,只需要任务提示词。
response = llm.invoke(message_history)
current_code = response.content
else:
print("\n>>> STAGE 1: REFINING code based on previous critique...")
# The message history now contains the task, the last code, and the last critique.
# We instruct the model to apply the critiques.
# 后续迭代时,除了任务提示词,还包含上一步的代码和反馈。
# 然后要求模型根据反馈意见优化代码。
message_history.append(HumanMessage(content="Please refine the code using the critiques provided."))
response = llm.invoke(message_history)
current_code = response.content
print("\n--- Generated Code (v" + str(i + 1) + ") ---\n" + current_code)
message_history.append(response) # Add the generated code to history
# --- 2. REFLECT STAGE ---
# --- 反思阶段 ---
print("\n>>> STAGE 2: REFLECTING on the generated code...")
# Create a specific prompt for the reflector agent.
# This asks the model to act as a senior code reviewer.
# 创建一个特定的提示词,要求模型扮演高级软件工程师的角色,对代码进行仔细的审查。
reflector_prompt = [
SystemMessage(content="""
You are a senior software engineer and an expert in Python.
Your role is to perform a meticulous code review.
Critically evaluate the provided Python code based on the original task requirements.
Look for bugs, style issues, missing edge cases, and areas for improvement.
If the code is perfect and meets all requirements, respond with the single phrase 'CODE_IS_PERFECT'.
Otherwise, provide a bulleted list of your critiques.
"""),
HumanMessage(content=f"Original Task:\n{task_prompt}\n\nCode to Review:\n{current_code}")
]
critique_response = llm.invoke(reflector_prompt)
critique = critique_response.content
# --- 3. STOPPING CONDITION ---
# 如果代码完美符合要求,则结束反思循环。
if "CODE_IS_PERFECT" in critique:
print("\n--- Critique ---\nNo further critiques found. The code is satisfactory.")
break
print("\n--- Critique ---\n" + critique)
# Add the critique to the history for the next refinement loop.
message_history.append(HumanMessage(content=f"Critique of the previous code:\n{critique}"))
print("\n" + "="*30 + " FINAL RESULT " + "="*30)
print("\nFinal refined code after the reflection process:\n")
print(current_code)
if __name__ == "__main__":
run_reflection_loop()译者注:Colab 代码 已维护在此处,同时补充了输出结果作为参考。
代码首先设置环境、加载 API 密钥,并初始化 GPT-4o 模型,使用低温度值以获得稳定的输出。核心任务由一个提示定义,要求创建一个计算阶乘的 Python 函数,要求包含完整的文档、处理边界情况(如 0 的阶乘)、以及对负数输入的错误处理。
run_reflection_loop
函数负责协调整个迭代优化过程。在循环中,第一次迭代由大语言模型基于任务提示生成初始代码;之后的迭代则根据上一步给出的建议优化代码。
还有一个独立的「反思者」角色,同样由大语言模型扮演但使用不同系统提示。它以高级软件工程师的身份来评审生成的代码是否符合原始需求,并以问题列表的形式提供反馈意见,或在没有发现问题时返回 CODE_IS_PERFECT。循环会持续进行,直到评审认为代码已无可改进或达到最大迭代次数。
会话历史在每一步都会保留并传递给语言模型,为生成、改进和反思阶段提供上下文。最后,脚本在循环结束时打印出最终代码版本。
实战示例:使用 Google ADK
现在我们来看一个使用 Google ADK 实现的示例。具体来说,代码采用「生成器-评论者」架构来演示反思模式,其中一个组件(生成器)产生初始结果或方案,另一个组件(评论者)提出反馈建议,帮助生成器不断改进,最终得到更完善、更准确的输出。
from google.adk.agents import SequentialAgent, LlmAgent
# Colab 代码链接:https://colab.research.google.com/drive/1nwE2GH6c08dGlvAv7T28uF1xe2qeu2q_
# The first agent generates the initial draft.
# 第一个智能体生成初始草稿。
generator = LlmAgent(
name="DraftWriter",
description="Generates initial draft content on a given subject.",
instruction="Write a short, informative paragraph about the user's subject.",
output_key="draft_text" # The output is saved to this state key.
)
# The second agent critiques the draft from the first agent.
# 第二个智能体评审第一个智能体的草稿。
reviewer = LlmAgent(
name="FactChecker",
description="Reviews a given text for factual accuracy and provides a structured critique.",
instruction="""
You are a meticulous fact-checker.
1. Read the text provided in the state key 'draft_text'.
2. Carefully verify the factual accuracy of all claims.
3. Your final output must be a dictionary containing two keys:
- "status": A string, either "ACCURATE" or "INACCURATE".
- "reasoning": A string providing a clear explanation for your status, citing specific issues if any are found.
""",
output_key="review_output" # The structured dictionary is saved here.
)
# The SequentialAgent ensures the generator runs before the reviewer.
# 确保生成者在评论者之前运行。
review_pipeline = SequentialAgent(
name="WriteAndReview_Pipeline",
sub_agents=[generator, reviewer]
)
# Execution Flow:
# 1. generator runs -> saves its paragraph to state['draft_text'].
# 2. reviewer runs -> reads state['draft_text'] and saves its dictionary output to state['review_output'].
# 执行流程:
# 1. 生成者运行 -> 将其段落保存到 state['draft_text']。
# 2. 评论者运行 -> 读取 state['draft_text'] 并将其字典输出保存到 state['review_output']。该示例展示了在 Google ADK 中使用顺序智能体管道来生成和审查文本。它定义了两个 LlmAgent 实例:generator 和 reviewer。生成器智能体负责根据指定主题撰写一段简短且信息量高的初稿,并将结果存为状态键 draft_text。审查者智能体则作为事实核查者,从 draft_text 读取内容并核实事实准确性。审查者的输出是一个结构化字典,包含两个键:status 和 reasoning,其中状态的值包括 ACCURATE 和 INACCURATE,而 reasoning 字段是对状态判断的补充说明,具体的值保存在状态键 review_output。
然后通过名为 review_pipeline 的 SequentialAgent 来控制两个智能体的执行顺序,确保先执行生成器智能体,再执行审查者智能体。整体流程是生成器先生成并保存文本,然后审查者读取状态并执行事实核查,再将核查发现的内容保存回状态。这种管道化的设计便于用独立的智能体完成结构化的内容创作与审查。注意: 对于感兴趣的用户,还可使用 ADK 的 LoopAgent 实现类似功能。
在结束前需要注意,虽然反思模式能显著提升输出质量,但也有重要的权衡。其迭代过程虽有效,却可能带来更高的成本和更长的延迟,因为每次改进往往都要发起一次新的模型调用,因此对时间敏感的场景并不适合。另外,该模式占用的内存也会较多,因为随着每轮迭代的进行,会话历史会不断增长,包含最初的输出、评价意见和后续的改进内容。
要点速览
问题所在: 智能体的初始输出通常不够理想,存在不准确、不完整或未能满足复杂要求的问题。基本智能体工作流缺乏内置过程让智能体识别和修复自己的错误。为了解决这一点,可以让智能体先自我评估,或通过引入独立的智能体来审查和指出问题,确保初始回答不会直接作为最终结果。
解决之道: 反思模式通过引入自我纠错和改进机制来解决问题。它建立反馈循环,其中「生产者」智能体生成输出,然后「评论者」智能体(或生产者本身)根据预定义标准评估输出。相关的反馈建议随后用于生成改进版本。这种生成、评估和优化的迭代过程逐步提高最终结果的质量,产生更准确、连贯和可靠的结果。
经验法则: 当最终输出的质量、准确性和细节比速度和成本更重要时应考虑使用反思模式。它对于生成高质量的长篇内容、编写和调试代码、创建详细计划等任务非常有效。当任务需要更高的客观性或涉及专业评估(常规生产者可能会遗漏),建议采用独立的评论者智能体以提高输出质量。
可视化总结:
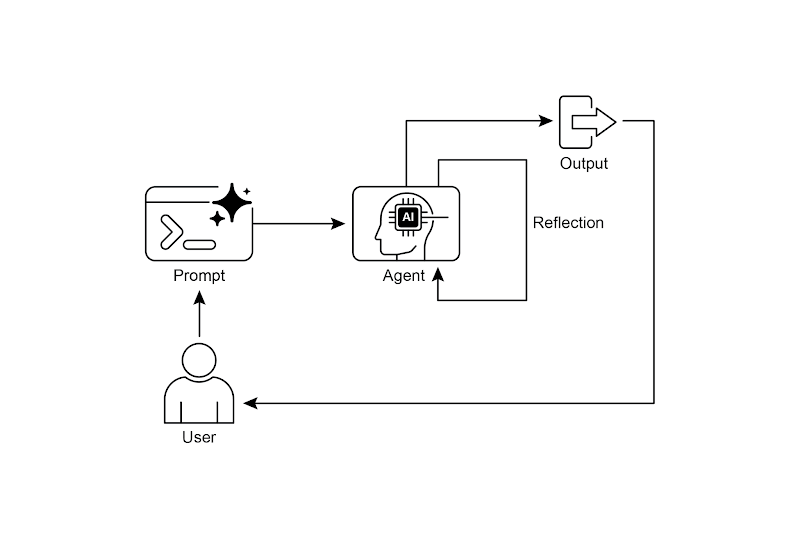
图 1:反思设计模式之自我反思
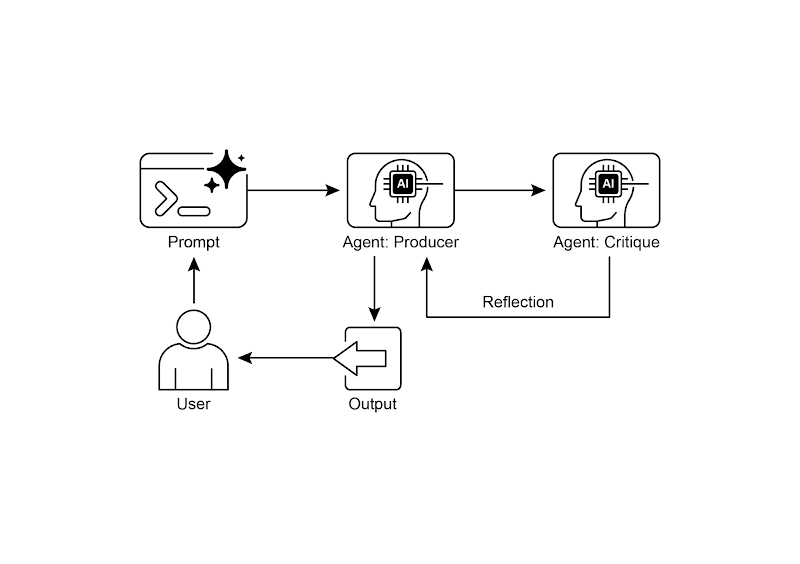
图 2:反思设计模式之生产者和评论者智能体
核心要点
- 反思模式的主要优势在于它可以通过反复自我修正和改进输出,显著提高质量、准确性和遵循更复杂的指令。
- 它包括执行、评估/评价和改进的反馈循环。对于需要高质量、准确性或细腻表述的任务,反思是不可或缺的。
- 一个有效的方法是采用「生产者-评论者」模型,由一个独立的智能体(或基于提示的不同角色)来评估初始输出。通过职责分离可以提高评判的客观性,并提供更专业、更有条理的反馈。
- 然而,这些好处以增加延迟和成本为代价,同时还有超出模型上下文窗口或被 API 服务限流的风险。
- 虽然完整的迭代反思通常依赖有状态的工作流(例如 LangGraph),但在 LangChain 中也可以用 LCEL 实现一次性的反思步骤,将生成的输出传给评论者以进行评审并据此改进。
- Google ADK 可以通过一系列串联的工作流程来促进反思:一个智能体生成输出,另一个智能体对其进行评审,并据此进行后续改进。
- 该模式使代理能够自我修正,并随着时间不断提高表现。
结语
反思模式为代理的工作流程提供了自我修正的关键手段,使其能通过多次迭代而不是一次性完成任务来持续改进。具体做法是形成一个循环:系统先生成初稿,然后按照既定标准对其进行评估,最后根据评估结果生成更完善的输出。这种评估既可以由智能体自己完成(自我反思),也可以由一个专门的评论者智能体来执行。通常后一种方式更有效,也是该模式的一个重要架构决策。
虽然要实现完全自主的多步骤反思需要可靠的状态管理架构,但其核心思想可以通过「生成—评审—改进」的循环清晰地呈现。作为一种控制结构,反思可以与其他基础模式结合使用,从而构建更稳健、功能更强大的智能体系统。
参考文献
以下是有关反思模式和相关概念的进一步阅读资源:
- 使用强化学习训练语言模型以实现自我纠正,https://arxiv.org/abs/2409.12917
- LangChain 表达式语言文档:https://python.langchain.com/docs/introduction/
- LangGraph 文档:https://www.langchain.com/langgraph
- Google 智能体开发套件 (ADK) 文档(多智能体系统):https://google.github.io/adk-docs/agents/multi-agents/