昨天,人工智能领域的前沿公司 Anthropic 推出了他们最新的 AI 模型 -- Claude 3.7 Sonnet。这不仅是 Claude 模型家族的又一次重大升级,更是在 AI 辅助编程领域树立了一个新的标杆。这款模型不仅拥有强大的通用智能,更在编程方面实现了质的飞跃,能够像一位经验丰富的程序员一样,帮助你编写代码、调试程序、甚至独立完成复杂的开发任务。本文将带你深入了解 Claude 3.7 Sonnet 的强大功能、实际表现,以及它将如何改变我们编写代码的方式。
不只是快,更会"思考":Claude 3.7 Sonnet 的混合推理引擎
Claude 3.7 Sonnet 最厉害的地方,在于它拥有一个"混合推理引擎"。你可以把它想象成一个既能快速反应,又能深入思考的大脑。这种独特的设计,让它在处理各种任务时都能游刃有余。
两种思考模式,灵活应对各种任务

传统的 AI 模型,通常只有一种"思考"方式。要么像"急性子",对简单的问题或指令能立刻给出答案,但在面对复杂问题时就显得力不从心;要么像"慢性子",能深入思考复杂问题,但反应速度又太慢。Claude 3.7 Sonnet 打破了这种局限,它有两种思考模式:
- 快速响应模式: 就像我们平时聊天一样,对于一些简单的问题,比如"今天天气怎么样?"或者"帮我写一句生日祝福",它能立刻给出答案。
- 扩展思考模式: 当面对复杂的难题,比如"请解释一下量子力学的基本原理",或者"帮我设计一个电商网站的数据库结构",它会像一位经验丰富的专家一样,进行更长时间、更深入、更全面的思考,一步步推理,最终给出高质量的答案。这种模式在处理数学、物理、编程等需要逻辑推理的任务时,效果尤其显著。
更棒的是,如果你是开发者,通过 API 使用 Claude 3.7 Sonnet,你还能精确控制它"思考"的时间。这就像给 AI 装上了一个"思考加速器",你可以根据任务的难易程度,调整它的思考速度。比如,对于一个简单的代码补全任务,你可以让它快速响应;而对于一个复杂的代码重构任务,你可以让它多思考一会儿,以获得更优的方案。这种灵活的控制方式,既保证了工作效率,又保证了结果的质量。
案例:蒙提霍尔问题
为了更直观地展示扩展思考模式的威力,Anthropic 举了一个经典的概率论问题 -- 蒙提霍尔问题(Monty Hall problem)作为例子。在这个问题中,Claude 3.7 Sonnet 能够在开启扩展思考模式后,详细地列出每一步的推理过程(思维链,Chain-of-Thought),最终得出正确的答案,整个过程仅需 52 秒。
不只追求高分,更注重实用
Anthropic 在开发 Claude 3.7 Sonnet 时,有一个明确的目标:不仅仅在各种测试中拿到高分,更要让模型在实际工作中发挥作用,真正帮助到用户。他们希望 Claude 3.7 Sonnet 能够成为开发者、研究人员、以及各行各业人士的得力助手。
正如 Anthropic 官方所说:"我们更关注的是模型在真实世界任务中的表现,而不是在一些竞赛题目上的得分。" 这种务实的设计理念,使得 Claude 3.7 Sonnet 在处理实际问题时,表现得更加出色。
更友好的交互体验
在与 AI 模型交互的过程中,我们有时会遇到模型"拒绝回答"的情况。这可能是因为问题太复杂、太模糊,或者模型认为问题涉及敏感信息。与之前的版本相比,Claude 3.7 Sonnet 在这方面做了很大的改进。它的"拒绝率"降低了 45%,同时保持了对安全性的高度重视。这意味着当你向它提问时,它更有可能给你一个有用的答案,而不是简单地说"我不知道"或"我不能回答这个问题"。这种改进,大大提升了用户的使用体验。
价格和获取方式
Claude 3.7 Sonnet 的定价与前代 Sonnet 模型保持一致,非常具有竞争力:
- 输入:每百万 tokens 3 美元
- 输出:每百万 tokens 15 美元(这个价格包含了模型"思考"所消耗的 tokens)
目前,你可以在所有 Claude 计划中使用 Claude 3.7 Sonnet,无论你是免费用户,还是 Pro、Team 或 Enterprise 版本的付费用户,都可以体验到这款新模型的强大功能。此外,你还可以通过 Anthropic API、Amazon Bedrock 和 Google Cloud Vertex AI 这些平台来使用 Claude 3.7 Sonnet。不过,需要注意的是,"扩展思考模式"目前只在付费计划中提供。
全面测试:Claude 3.7 Sonnet 的实力有多强?
为了全面评估 Claude 3.7 Sonnet 的能力,Anthropic 和其他独立机构对它进行了各种各样的测试。测试结果表明,Claude 3.7 Sonnet 在多个领域都达到了业界领先水平,展现出强大的综合实力。
基准测试:多项能力名列前茅
下面这张表格,详细列出了 Claude 3.7 Sonnet 在一些关键基准测试中的表现:
| 测试项目 | 描述 | Claude 3.7 Sonnet 表现 |
|---|---|---|
| 研究生级别推理 (GPQA Diamond) | 考察模型在研究生级别难题上的推理能力,题目通常涉及多个学科的知识。 | Claude 3.7 Sonnet 在此项测试中表现出色,尤其在启用扩展思考模式后,展现出强大的逻辑推理和知识运用能力。 |
| Agentic 编码 (SWE-bench Verified) | 评估模型解决 GitHub 上真实软件问题的能力。 | Claude 3.7 Sonnet 在此项测试中 大幅领先 于其他模型,证明了其在解决实际软件问题方面的卓越能力。 |
| Agentic 工具使用 (TAU-bench) - Retail | 评估 AI 代理在复杂任务中与用户和工具交互的能力(零售场景)。 | Claude 3.7 Sonnet 在此项测试中表现最佳,展现出在复杂交互任务中的优势。 |
| Agentic 工具使用 (TAU-bench) - Airline | 评估 AI 代理在复杂任务中与用户和工具交互的能力(航空场景)。 | Claude 3.7 Sonnet 在此项测试中同样表现最佳,进一步证明了其在复杂交互任务中的领先地位。 |
| 多语言问答 (MMMLU) | 评估模型在不同语言环境下的理解和问答能力。 | Claude 3.7 Sonnet 在此项测试中表现优秀,展现出良好的多语言理解能力。 |
| 视觉推理 (MMMU) | 考察模型理解和分析图片的能力。 | Claude 3.7 Sonnet 在此项测试中表现良好,具备一定的视觉理解能力。 |
| 指令跟随 (IFEval) | 评估模型理解和执行复杂指令的能力。 | Claude 3.7 Sonnet 在此项测试中表现出色,能够准确理解和执行复杂指令。 |
| 数学问题解决 (MATH 500) | 考察模型解决各种数学问题的能力。 | Claude 3.7 Sonnet 在此项测试中表现良好. |
| 高中数学竞赛 (AIME 2024) | 考察模型在高中数学竞赛中的表现。 | Claude 3.7 Sonnet 在此项测试中表现尚可. |
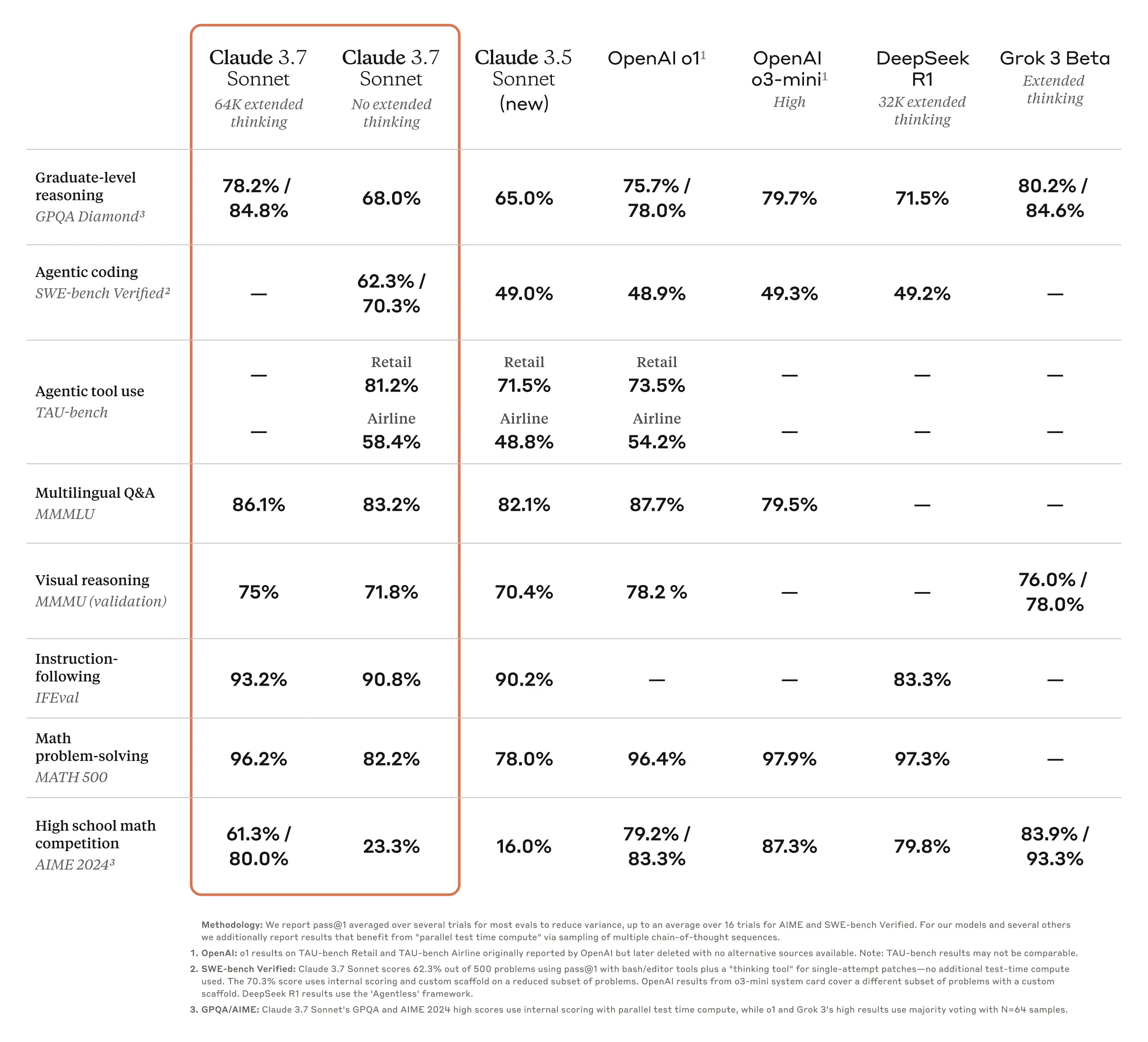
从这些测试结果可以看出,Claude 3.7 Sonnet 不仅在传统的文本理解、推理、问答等方面表现出色,在视觉理解、指令跟随等方面也达到了很高的水平。更重要的是,它在专门针对编程能力的测试中取得了最佳成绩,这表明 Claude 3.7 Sonnet 在 AI 辅助编程方面具有巨大的潜力。
智能体交互能力测试
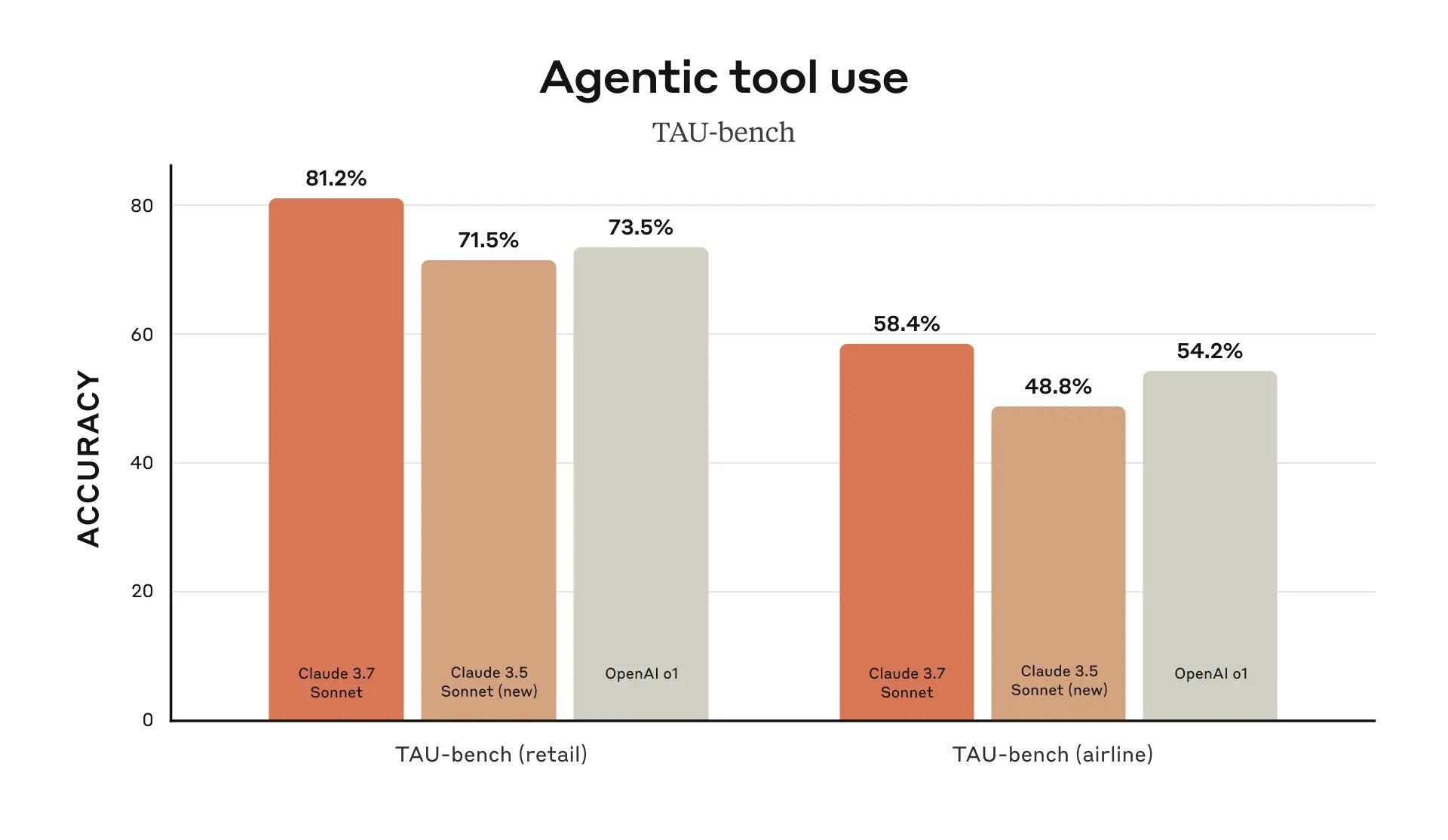
Claude 3.7 Sonnet 在 TAU-bench 的 Agentic Tool Use 测试中刷新 SOTA, 这表明它在复杂交互任务中具有显著优势。
更安全、更可靠
Anthropic 非常重视 AI 模型的安全性。他们深知,一个强大的 AI 模型,如果不能保证安全可靠,就可能带来潜在的风险。因此,他们在 Claude 3.7 Sonnet 的开发过程中,投入了大量精力来提升模型的安全性和可靠性。
他们对 Claude 3.7 Sonnet 进行了大量的测试,包括内部测试和外部专家的评估,以确保模型不会产生有害、歧视性或误导性的内容。此外,他们还特别关注模型在面对"提示注入"等新型攻击时的表现,并采取了多种措施来增强模型的防御能力。
Anthropic 还发布了一份详细的 "系统卡"(system card),公开了 Claude 3.7 Sonnet 的安全评估结果和相关技术细节。这种透明的做法,有助于提升公众对 AI 模型的信任度。
Claude 3.7 Sonnet:AI 编程能力的革新
如果说 Claude 3.7 Sonnet 在通用智能方面已经足够出色,那么它在编程方面的能力,则可以用"惊艳"来形容。它不仅能够帮助开发者更快、更好地编写代码,还能像一位经验丰富的程序员一样,独立思考、自主决策,完成复杂的编程任务。
Agentic 编码:AI 编程的未来
要理解 Claude 3.7 Sonnet 在编程方面的优势,首先需要了解一个概念 -- Agentic 编码。
传统的 AI 编程工具,比如代码补全、代码生成,主要起到的是"助手"的作用。它们可以帮你写一些简单的代码片段,或者根据你的注释自动生成代码,但它们并不能独立完成一个完整的编程项目。
而 Agentic 编码则不同。它赋予了 AI 模型更强的自主性,让 AI 能够像一个真正的程序员一样,理解项目需求、设计代码结构、编写代码、调试程序、甚至与其他工具协同工作,最终独立完成一个完整的项目。
Claude 3.7 Sonnet 在 Agentic 编码方面表现非常出色,这主要得益于以下两个方面:
- 混合推理引擎: 前面提到,Claude 3.7 Sonnet 拥有一个"混合推理引擎",这使得它既能快速响应简单的编程指令,又能进行深入的思考,解决复杂的编程难题。
- 实际应用导向: Anthropic 在开发 Claude 3.7 Sonnet 时,更注重模型在实际编程任务中的表现,而不是在一些"玩具"代码上的得分。
权威测试:证明 Claude 3.7 Sonnet 的编程实力
为了客观评估 AI 模型在编程方面的能力,业界有一些权威的测试,其中最具代表性的就是 SWE-bench Verified 和 TAU-bench。
- SWE-bench Verified: 这项测试会从 GitHub 上选取一些真实的软件问题,让 AI 模型尝试去解决。这些问题通常涉及多个代码文件,需要模型对整个项目有较好的理解,才能给出正确的解决方案。
- TAU-bench: 这项测试更加贴近实际的软件开发场景。它会模拟一个复杂的环境,让 AI 模型像人类开发者一样,与用户进行交互,使用各种工具(比如代码编辑器、调试器、版本控制系统等),来完成一个完整的软件开发任务。
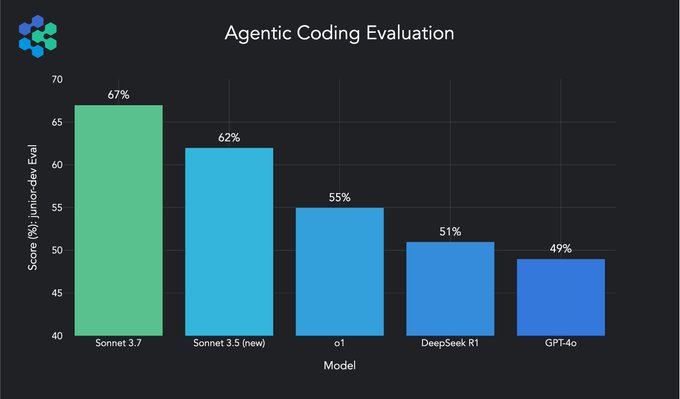
Claude 3.7 Sonnet 在这两项测试中都取得了目前最好的成绩,这充分证明了它在 Agentic 编码方面的领先地位。
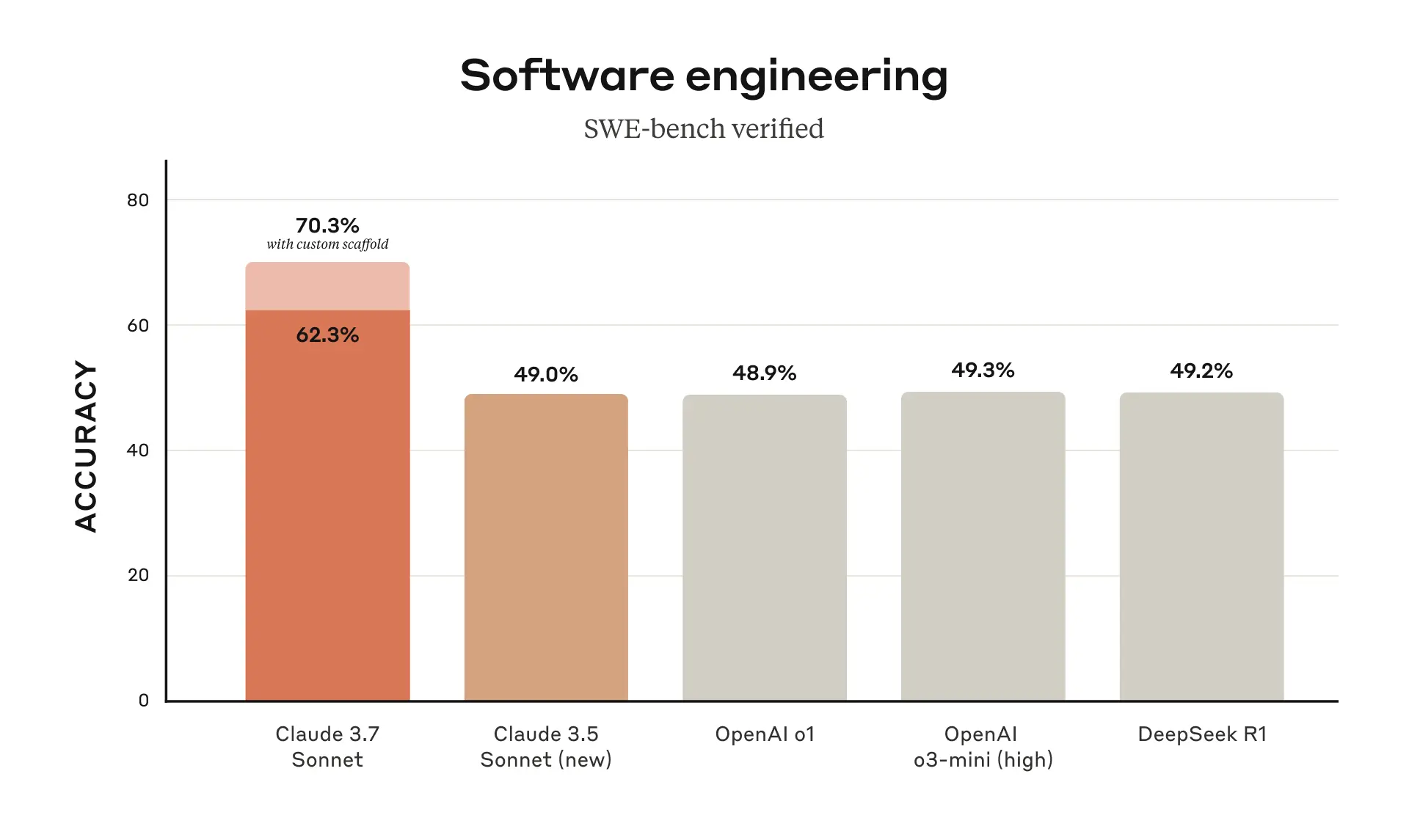
上图展示了 Claude 3.7 Sonnet 与其他 AI 模型在 Agentic Coding Evaluation 测试中的对比结果。可以看到,Claude 3.7 Sonnet 的得分明显高于其他模型,包括 Anthropic 自家的 Claude 3.5 Sonnet,以及 OpenAI 的模型。
行业大咖点赞:Claude 3.7 Sonnet 备受好评
Claude 3.7 Sonnet 的强大编程能力,不仅得到了权威测试的验证,还获得了众多开发者和企业的一致好评。
- Cognition Labs: 这家公司专注于 AI 软件开发,他们开发了一款名为 Devin 的 AI 程序员工具。Cognition Labs 将 Claude 3.7 Sonnet 集成到了 Devin 中,并表示:"在我们的测试中,Devin 与 Sonnet 3.7 能够自主实现一个中等规模的跨前端和后端的计费功能,这在以前是不可能实现的。Sonnet 3.7 是我们见过的在调试、代码库搜索和 Agentic 规划方面表现最好的模型。"
-
Cursor: Cursor 是一款广受欢迎的 AI 编程工具,许多开发者都在使用。Cursor 官方宣布,他们已经正式支持 Claude 3.7 Sonnet,并表示:"我们对 Sonnet 3.7 在实际 Agentic 任务中的编码能力印象非常深刻。它似乎是目前最先进的 AI 编程模型。"
-
bolt.new: 这是一家提供软件开发服务的公司。他们宣布将 Claude 3.7 Sonnet 应用于其关键的开发流程中。bolt.new 的团队表示:"在我们的测试中,Claude 3.7 Sonnet 在各个方面都比之前的版本有了显著的改进。我们对它的动态推理能力尤其感兴趣,这为我们的开发工作带来了新的可能性。"
-
Lex Fridman: Lex Fridman 是麻省理工学院的 AI 研究员,也是一位知名的科技博主。他表示:"对我来说,Sonnet 3.7 是目前为止在实际编程中用过的最好的模型。我在 Cursor 中切换到 Sonnet 3.7 后,感觉编码效率有了很大的提升。"
Claude Code:AI 编程的未来
除了 Claude 3.7 Sonnet 模型,Anthropic 还推出了一款名为 Claude Code 的工具。这是一款专门为开发者设计的 AI 编程助手,它可以与你的代码编辑器无缝集成,让你在编写代码的过程中,随时获得 AI 的帮助。值得一提的是,Claude Code 不仅仅是一个简单的代码补全工具,而是一个真正理解编程的 AI 助手。
Claude Code 具有以下特点:
- Agentic 编码: 就像前面介绍的,Claude Code 具备 Agentic 编码能力,能够像一位真正的程序员一样,独立完成复杂的编程任务。
- 终端集成: Claude Code 直接在你的终端中运行,无需额外的服务器或复杂的设置。在早期测试中,它能够一次性完成通常需要手动工作 45 分钟以上的任务,显著减少了开发时间和工作量。
- 代码库理解: Claude Code 能够理解整个代码库的上下文,而不仅仅是单个文件或代码片段。
- 自然语言交互: 你可以通过自然语言命令与 Claude Code 交互,让编码更高效、更直观。
- Github集成: 可以更方便的修改代码
- 安全保障: 有着权限管理系统,防止提示注入等攻击。
Claude Code 能主动与人协作,能够搜索和阅读代码、编辑文件、编写和运行测试、提交并将代码推送至 GitHub,以及使用命令行工具 -- 同时能够确保用户在每一步都能参与其中。
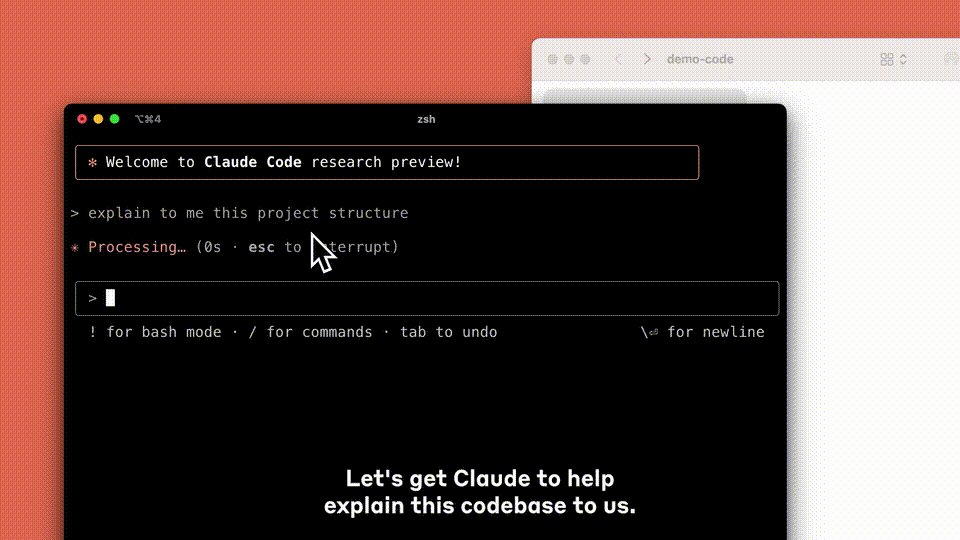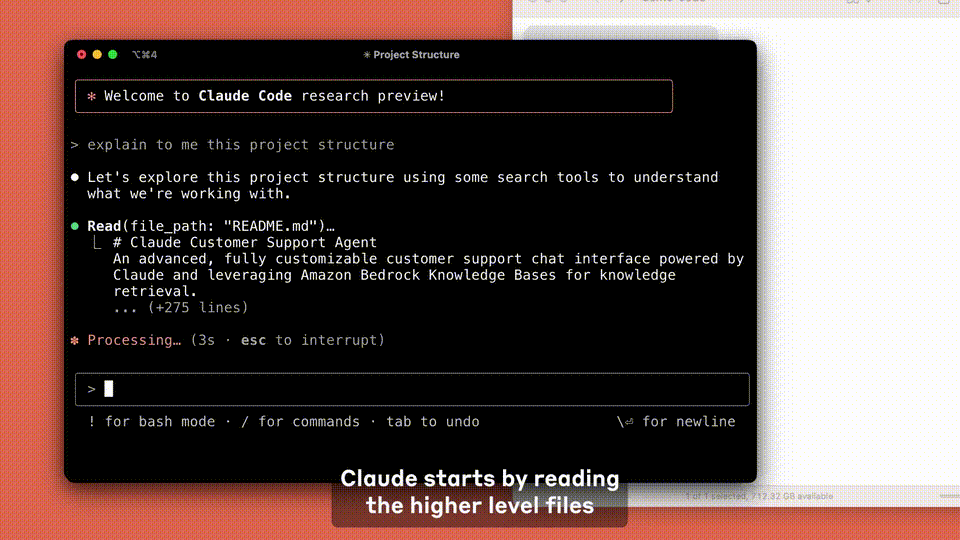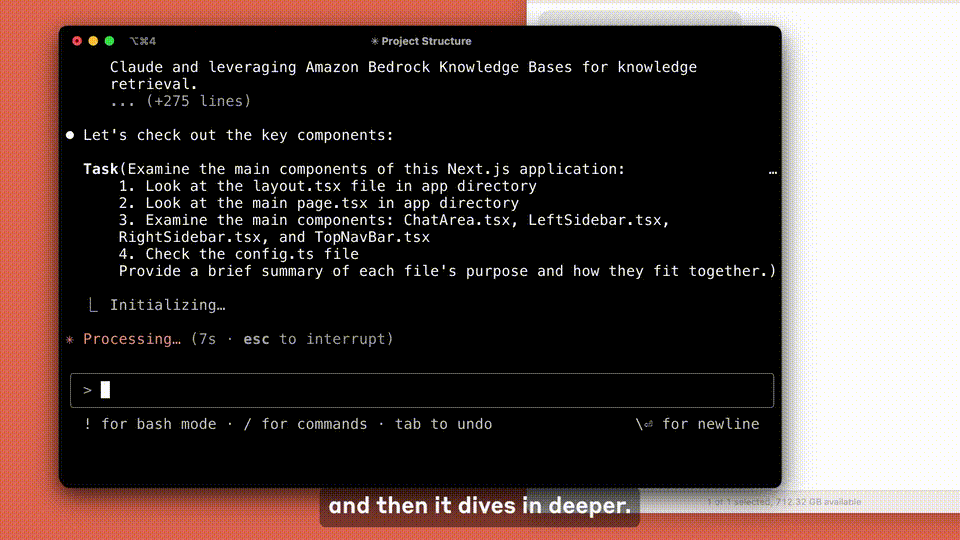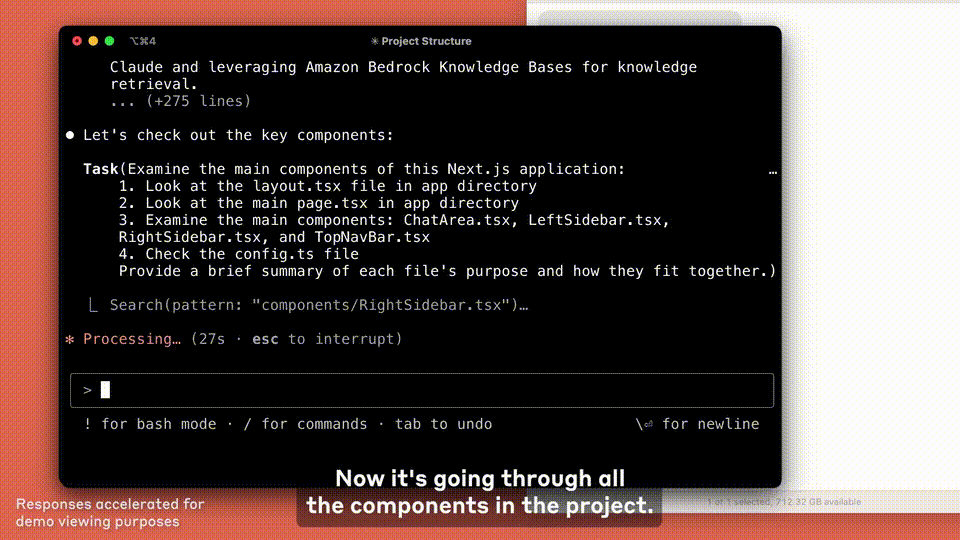
目前,Claude Code 还在测试阶段,你可以申请加入等待列表,提前体验这款工具。
在接下来的几周里,Anthropic 计划根据使用情况不断改进它:提升工具调用的可靠性、增加对长时间运行命令的支持、改进应用内渲染效果,并扩展 Claude 对自身能力的理解。
总结与展望
Claude 3.7 Sonnet 的发布,不仅是 Anthropic 公司技术实力的又一次展示,更是 AI 辅助编程领域的一个重要里程碑。从本文介绍的混合推理引擎到 Agentic 编码能力,从基准测试的优异表现到实际应用案例,我们可以清晰地看到这个模型在提升开发者生产力、赋能软件开发方面的巨大潜力。
Anthropic 在官方博客中展望未来时,描绘了一个令人兴奋的蓝图:AI 将逐步从助手、协作者,最终跃升为开拓者。

- 2024 年 - Claude 助手 (Claude assists): 专注于增强个体开发者的能力,帮助他们更好地完成当前的工作,让每个人都成为“最佳版本的自己”。
- 2025 年 - Claude 协作者 (Claude collaborates): 能够独立完成数小时的工作,达到专家水平,扩展个人和团队的能力边界。
- 2027 年 - Claude 开拓者 (Claude pioneers): 能够为具有挑战性的问题找到突破性的解决方案,而这些问题通常需要团队花费数年时间才能解决。这意味着 Claude 将具备高度的自主性、创造性和问题解决能力,能够在未知领域进行探索和创新。
总之,Claude 3.7 Sonnet 的发布,展示了 AI 辅助编程领域的新进展和潜力。它不仅是一款强大的工具,也能为开发者提供新的协作方式。我们期待开发者能够积极探索和利用这些新技术,与 AI 共同推动软件开发的进步。
