本文对市面上主流的 DeepSeek 模型 API 服务进行了全面的性能评测,包括火山引擎、OpenRouter 和 DeepSeek 官方等渠道。通过对首字响应时间、生成速度、服务稳定性等关键指标的测试,为开发者选择合适的 API 服务提供参考。本次测试主要用于评估个人生产环境中使用 DeepSeek 模型的可行性,包括对 DeepSeek-R1 和 DeepSeek-V3 版本的测试。
引言
最近在 使用 Dify 开发 Workflow 优化翻译流程 时,有网友推荐使用 DeepSeek-R1 来增强或对比翻译结果。然而,在实际测试过程中发现,多个渠道提供的 DeepSeek API 服务都存在不同程度的稳定性问题。在网友的推荐下,我决定对几个主要渠道进行全面的性能评测,以便为后续的生产部署选择最合适的服务提供商。
本次评测的设计受到了 赛博禅心测评文章 的启发。考虑到单次请求可能存在较大波动,我们扩展了测试方案:
- 更全面的测试数据: 从准备的 50 个测试问题中筛选出 12 个具有代表性的场景进行测试
- 并发性能测试: 使用 3 个并发线程执行测试,更贴近实际生产环境
- 完整数据记录: 将测试数据保存到 CSV 文件,便于后续分析和对比
需要特别说明的是,在测试过程中发现测试脚本对 DeepSeek 官网 API 的响应处理存在一些问题,这可能导致部分性能指标和成功率数据失真。但通过日志分析,我们仍能确认官方 API 在性能方面确实存在一定的问题,这与其他评测结果较为一致。
本文将详细分享测试过程和结果,希望能为开发者在选择 DeepSeek 模型 API 服务时提供有价值的参考。同时,我们也计划在后续补充更多渠道的测试,并与其他模型进行对比分析。
测试概述
本次评测重点关注以下几个方面:
-
首字响应时间(First Token Time)
- 衡量从发送请求到获得首个响应的时间
- 直接影响用户交互体验
- 对实时应用(如对话、翻译)尤为重要
-
生成速度(Generation Speed)
- 每秒生成的 token 数量(tokens/s)
- 反映模型的计算效率和吞吐量
- 影响长文本生成的整体耗时
-
服务稳定性
- 通过多次请求评估性能波动
- 统计最小值、最大值、平均值和 TP90
- 反映服务的可靠程度
-
请求成功率
- 衡量服务的可用性
- 影响实际应用的稳定性
测试目标
本次测试的主要目标是全面评估不同厂商/渠道提供的 DeepSeek 模型 API 的性能,具体包括以下几个方面:
-
首字响应时间 (First Token Time):
- 定义:模型接收到请求后,到开始输出第一个 token(通常是一个字或一个词)之间的时间间隔。
- 意义:反映了模型的启动速度、初始处理速度以及网络延迟。对于交互式应用(如聊天机器人、实时翻译等),首字响应时间直接影响用户体验。较低的首字响应时间可以带来更流畅、更自然的交互感受。
-
生成速度 (Generation Speed):
- 定义:模型每秒钟生成的 token 数量(tokens/s)。
- 意义:反映了模型的计算效率和吞吐量。生成速度越快,意味着模型在单位时间内能处理更多的文本生成任务,或者在相同时间内能生成更长的文本。
-
稳定性:
- 定义:通过多次请求评估性能波动
- 统计最小值、最大值、平均值和 TP90
- 反映服务的可靠程度
-
成功率 (Success Rate):
- 定义:API 请求成功的次数占总请求次数的百分比。
- 意义:反映了 API 服务的可靠性。一个成功率较低的 API,可能会导致应用频繁出错,影响用户体验和业务流程。
测试环境
为确保测试结果的可靠性和可重现性,我们采用了以下测试环境:
- 计算平台: Google Colab(免费版)
- 并发设置:
- 3 个并发线程
- 每个线程处理 4 个不同的 prompt
- 每个 prompt 发送 1 次请求
- 网络环境: 通过公网访问各服务提供商的 API
测试对象
本次评测选取了市面上主流的 DeepSeek 模型 API 服务提供商,涵盖了以下几个渠道:
| 服务提供商 | 模型版本 | API 端点/标识符 |
|---|---|---|
| 火山引擎 | DeepSeek-R1 | ep-20250217091332-8g29h |
| 火山引擎 | DeepSeek-V3 | ep-20250217102601-knmvv |
| OpenRouter | DeepSeek-R1 | deepseek/deepseek-r1 |
| OpenRouter | DeepSeek-V3 | deepseek/deepseek-chat |
| DeepSeek 官网 | DeepSeek-R1 | deepseek-reasoner |
| DeepSeek 官网 | DeepSeek-V3 | deepseek-chat |
需要说明的是,我们在初步测试中发现腾讯云和硅基流动的 TPS 和 TPM 非常低,仅适合个人使用和测试场景,不建议在生产环境中使用,因此未将其纳入本次正式评测范围。值得一提的是,硅基流动提供了 Pro 版本服务,可以申请更高的 TPS 限额,但由于申请流程尚未完成,本次暂未将其纳入评测范围,将在后续评测中进行跟进。
测试方法
我们采用了以下测试方法来确保评测的全面性和可靠性:
-
客户端配置
- 统一使用 OpenAI Python 客户端库
- 启用流式输出(
stream=True) - 开启 token 统计(
stream_options={"include_usage": True})
-
性能指标采集
- 记录首字响应时间
- 分别统计推理和生成阶段的耗时(如果支持)
- 计算生成速度(tokens/s)
- 追踪请求成功率
-
数据记录
- 使用 CSV 文件保存完整的请求信息
- 文件命名格式:
服务商名称_模型名称_时间戳 - 包含异常信息的捕获和记录
-
测试数据集
- 准备了 12 个不同类型的 prompt
- 涵盖文本解读、翻译、润色等多种任务
- 确保测试场景的多样性
测试 Prompt
为了全面评估模型在不同任务上的性能,我们准备了 12 个不同类型和长度的 prompt,涵盖了文本解读、翻译、文本润色、概念解释等多种任务,具体见下面的测试代码。
测试代码
以下是完整的测试脚本,包含了详细的注释,主要参考了 赛博禅心测评文章 的代码。
import time
import json
import csv
import concurrent.futures
import datetime
import pytz
import statistics
from openai import OpenAI
from google.colab import userdata
def test_provider(provider_config, prompts):
"""
测试单个提供商的 API,支持并发请求、多个 prompt,并将结果保存到 CSV 文件。
使用 OpenAI 客户端。
增加了平均首字时间和平均 token/s 的计算和输出。
"""
provider_name = provider_config.get("name", "Unnamed Provider")
model_name = provider_config.get("model", "Unknown Model")
num_threads = 3 # 设置为 3 个线程
num_prompts_per_thread = 4 # 每个线程处理的任务数
print(f"\n--- 开始测试服务商:{provider_name} (模型:{model_name}) (线程数: {num_threads}) ---")
api_key = userdata.get(provider_config["api_key_env"])
base_url = provider_config.get("base_url")
if not api_key:
print(f"错误:未找到 {provider_name} 的 API Key 环境变量 ({provider_config['api_key_env']})")
return
# 初始化 OpenAI 客户端
client = OpenAI(api_key=api_key, base_url=base_url)
def single_request(prompt):
"""
处理单个请求 (与原脚本计算逻辑一致)。
在请求结束日志中添加了指标信息。
"""
request_id = f"{provider_name}-{model_name}-{time.time()}"
print(f"[{request_id}] 请求开始: {prompt[:50]}...")
try:
start_time = time.time()
first_token_time = None
reasoning_tokens = 0
content_tokens = 0
prompt_tokens = 0
total_tokens = 0
reasoning_time = 0
content_time = 0
full_content = ""
error_message = ""
reasoning_start_time = None
content_start_time = None
last_reasoning_time = None
last_content_time = None
messages = [{"role": "user", "content": prompt}]
# 发起流式请求
response = client.chat.completions.create(
model=model_name,
messages=messages,
stream=True,
temperature=0.6,
stream_options={"include_usage": True},
)
for chunk in response:
if chunk.usage:
prompt_tokens = chunk.usage.prompt_tokens
completion_tokens = chunk.usage.completion_tokens
total_tokens = chunk.usage.total_tokens
if chunk.usage.completion_tokens_details is not None:
reasoning_tokens = chunk.usage.completion_tokens_details.reasoning_tokens
else:
reasoning_tokens = 0
content_tokens = completion_tokens - reasoning_tokens
if not chunk.choices:
continue
delta = chunk.choices[0].delta
reasoning_piece = getattr(delta, 'reasoning_content', "")
content_piece = getattr(delta, 'content', "")
if first_token_time is None and (reasoning_piece or content_piece):
first_token_time = time.time() - start_time
current_time = time.time()
if reasoning_piece:
if reasoning_start_time is None:
reasoning_start_time = current_time
if last_reasoning_time is not None:
reasoning_time += current_time - last_reasoning_time
last_reasoning_time = current_time
full_content += reasoning_piece
elif content_piece:
if content_start_time is None:
content_start_time = current_time
if last_reasoning_time is not None:
reasoning_time += last_reasoning_time - reasoning_start_time
if last_content_time is not None:
content_time += current_time - last_content_time
last_content_time = current_time
full_content += content_piece
total_time = time.time() - start_time
if content_start_time is not None and last_content_time is not None:
content_time += time.time() - last_content_time
# 计算本次请求的 tokens/s
tokens_per_second = completion_tokens / total_time if total_time > 0 else None
print(
f"[{request_id}] 请求结束, "
f"首字时间: {first_token_time:.3f}s, "
f"推理tokens: {reasoning_tokens}, "
f"推理时间: {reasoning_time:.3f}s, "
f"内容tokens: {content_tokens}, "
f"内容时间: {content_time:.3f}s, "
f"总tokens: {total_tokens}, "
f"总时间: {total_time:.3f}s, "
f"tokens/s: {tokens_per_second:.2f}" if tokens_per_second is not None else "tokens/s: N/A"
)
return {
"provider": provider_name,
"model": model_name,
"prompt": prompt,
"first_token_time": round(first_token_time, 3) if first_token_time is not None else None,
"reasoning_tokens": reasoning_tokens if reasoning_tokens > 0 else None,
"reasoning_time": round(reasoning_time, 3) if reasoning_time > 0 else None,
"content_tokens": content_tokens,
"content_time": round(content_time, 3) if content_time > 0 else None,
"total_tokens": total_tokens,
"total_time": round(total_time, 3),
"full_content": full_content,
"temperature": 0.6,
"error": error_message,
"success": True,
"completion_tokens": completion_tokens,
}
except Exception as e:
return process_error(f"发生错误:{e}", prompt)
def process_error(error_message, prompt):
"""处理错误,返回错误信息字典"""
request_id = f"{provider_name}-{model_name}-{time.time()}"
print(f"[{request_id}] 请求错误: {error_message}")
return {
"provider": provider_name,
"model": model_name,
"prompt": prompt,
"first_token_time": None,
"reasoning_tokens": None,
"reasoning_time": None,
"content_tokens": None,
"content_time": None,
"total_tokens": None,
"total_time": None,
"full_content": None,
"temperature": 0.6,
"error": error_message,
"success": False,
"completion_tokens": None,
}
# 使用 ThreadPoolExecutor,固定 3 个线程
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
#futures = [executor.submit(single_request, prompt) for prompt in prompts] # 原来的方式
futures = [executor.submit(single_request, prompt) for prompt in prompts[:num_threads * num_prompts_per_thread]]
results = [future.result() for future in concurrent.futures.as_completed(futures)]
timestamp = datetime.datetime.now(pytz.timezone('Asia/Shanghai')).strftime('%Y%m%d_%H%M%S')
csv_filename = f"results_{provider_name.replace('/', '_')}_{model_name.replace('/', '_')}_{timestamp}.csv"
with open(csv_filename, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ["provider", "model", "prompt", "first_token_time", "reasoning_tokens",
"reasoning_time", "content_tokens", "content_time", "total_tokens", "total_time",
"full_content", "temperature", "error", "success", "completion_tokens"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(filter(None, results))
success_count = sum(1 for r in results if r and r['success'])
failure_count = len(results) - success_count
total_requests = len(results)
success_rate = (success_count / total_requests) * 100 if total_requests > 0 else 0.0
valid_first_token_times = [
r['first_token_time'] for r in results if r and r['success'] and r['first_token_time'] is not None
]
avg_first_token_time = statistics.mean(valid_first_token_times) if valid_first_token_times else None
valid_completion_tokens = [
r['completion_tokens'] for r in results if r and r['success'] and r['completion_tokens'] is not None
]
valid_total_times = [r['total_time'] for r in results if r and r['success'] and r['total_time'] is not None]
if len(valid_completion_tokens) > 0 and len(valid_completion_tokens) == len(valid_total_times):
avg_tokens_per_second = statistics.mean(
[tokens / time for tokens, time in zip(valid_completion_tokens, valid_total_times)]
) if valid_total_times else None
else:
avg_tokens_per_second = None
print(f"测试完成, 结果已保存到文件: {csv_filename}")
print(f"总请求数: {total_requests}, 成功数: {success_count}, 失败数: {failure_count}, 成功率: {success_rate:.2f}%")
if avg_first_token_time is not None:
print(f"平均首字时间: {avg_first_token_time:.3f} 秒")
else:
print("平均首字时间: 无法计算 (没有成功的请求或首字时间数据)")
if avg_tokens_per_second is not None:
print(f"平均 token/s: {avg_tokens_per_second:.2f}")
else:
print("平均 token/s: 无法计算 (没有成功的请求或 token/时间数据)")
if __name__ == "__main__":
prompts = [
# 文本任务 (10个)
"解读一下这条推文:'@naval The currency of life isn't money. It is not even time. It's attention.' 请结合 Naval Ravikant 的背景和观点进行解释。",
"将以下中文推文翻译成英文,并以自然的口感回复给推特网友:'目前的流程和提示词仅支持英文翻译为中文,不过只要适当调整一下流程和提示词,应该可以支持任意语言的翻译。'",
"帮我润色并扩充这篇推文,使其更适合在技术社区 V2EX 上发布,并吸引开发者关注:\n```\n花了两天和 Cursor 重新设计了个人博客,这风格实在是太爱了,最近把之前的文章搬过来,2025 年好好写博客。\n博客是基于 Next.js 和 mdx 的静态博客,可以在本地使用 cursor 编写文章。\n网址:ginonotes.com\n```",
"将以下段落用中文重写,保持原有含义,使其更符合中文技术博客的表达习惯:\n```\nWhen building LLM applications, you'll probably want to experiment with different cognitive architectures just as frequently as you experiment with prompts. We're building LangChain and LangGraph to enable that. Most of our development efforts over the past year have gone into building low-level, highly controllable orchestration frameworks (LCEL and LangGraph). \nThis is a bit of a departure from early LangChain which focused on easy-to-use, off-the-shelf chains. These were great for getting started but tough to customize and experiment with. This was fine early on, as everyone was just trying to get started, but as the space matured, the design pretty quickly hit its limits.\n```",
"为以下文章撰写一段摘要(约150字),要求概括文章的核心观点、主要内容和结论:\n```\n围绕 DeepSeek 成就的广泛叙述引发了关于 Scaling Law的论断。行业有理由质疑模型性能是否总是越大越好。但这种观点忽略了关键的转变:我们看到的并非是scaling的终结,而是其向新维度的演变。正如我们在 "2025 State of AI"(https://www.leoniscap.com/deep-dives/the-state-of-ai-in-2025)报告中提到的那样,行业正从一个由预训练扩展(Pre-training Scaling)主导的时代转向一个后训练优化(Post-training Optimization)提供巨大未开发潜力的时代。\nAnthropic 的 CEO Dario Amodei 也指出,后训练阶段扩展 / Post-training Scaling机会可能会带来比传统预训练扩展 / Pre-training Scaling更大的改进。从 2020 年到 2023 年,主要scaling的是在互联网文本上训练的预训练模型。随着这种"大力出奇迹"方法带来的性能提升走到尽头,像 OpenAI 和 Anthropic 这样的厂商转向使用强化学习和思维链 / CoT作为新的 Scaling 重点。这种方法在提高数学、编码和科学推理等可衡量任务的性能方面特别有效。在 2025 年,我们可以期待这种以后训练为中心的Scaling会带来更多成果,包括更复杂的强化学习方法、更好的合成数据生成以及更高效的推理时计算——这些领域我们才刚刚开始探索。\n然而,DeepSeek 的成就确实表明,支出与性能之间的关系并非线性。通过像 MoE 和 MLA 这样的架构创新,他们用更少的资源实现了更多的成果——这类似于半导体行业在 2000 年代末遇到 CPU 时钟速度墙时的演变。正如芯片制造商在原始时钟速度之外找到了新的改进向量——多核架构、先进封装和并行计算——AI 开发并非撞上了墙,而是在多样化其扩展向量。 \n主要大模型厂商的行动支持了这种更细致的观点。大型模厂商仍在继续进行大规模的基础设施投资。OpenAI 刚刚宣布了其 5000 亿美元的 Stargate 基础设施计划,xAI 推出了其 10 万卡 GPU 的 Colossus 超级数据中心,Meta 正在计划 2026 年的 2GW的数据中心,其他公司也在预测数十亿美元的 AI 开发投资。这些投资表明,Scaling 并未终结——它正在演变。未来可能会同时出现这两种情况:通过架构创新继续提高效率,以及进行大规模基础设施投资以推动可能性的边界。\n```",
"总结以下这段文字的主要观点(不超过三句话),并分析作者可能存在的偏见或局限性:\n```\nAnthropic 的 CEO Dario Amodei 在报告中说,几周前,我曾撰文呼吁美国应加强对华芯片出口管制。此后不久,中国人工智能公司 DeepSeek 便成功地——至少在某些方面——以更低的成本,实现了与美国顶尖人工智能模型相近的性能水平。\n在此,我暂且不讨论 DeepSeek 是否对 Anthropic 等美国人工智能企业构成威胁(尽管我认为许多关于 DeepSeek 威胁美国人工智能领导地位的说法被严重夸大了)。\n我更关注的是,DeepSeek 的成果发布是否削弱了芯片出口管制政策的合理性。我的看法是否定的。事实上,我认为 DeepSeek 的进展反而令出口管制政策显得比一周前更具存在意义上的重要性。\n出口管制服务于一个至关重要的目标:确保民主国家在人工智能发展中保持领先地位。需要明确的是,出口管制并非逃避美中竞争的手段。最终,如果美国和其他民主国家的 AI 公司想要胜出,就必须开发出比中国更卓越的模型。但是,在力所能及的情况下,我们不应将技术优势拱手让给中国。\n```",
"将以下新闻标题改写成更吸引眼球的形式,并分别针对科技爱好者、普通大众和投资者三个群体进行改写:\n'Anthropic 创始人发声:DeepSeek 事件前所未有,美国要继续加强出口管制'",
"为以下产品描述生成3个不同的社交媒体帖子,分别适用于 Twitter、Facebook 和 LinkedIn,并考虑不同平台的特点和受众:\n```\n文润是一个基于先进 AI 技术的智能文本润色平台。通过多轮评审和优化的 AI 工作流,我们能帮助用户快速提升文本质量,解决传统文本创作中耗时费力、质量不稳定、翻译生硬等痛点问题。无论是技术文档、学术论文、营销文案还是日常写作,文润都能让您的文字更加清晰、准确、流畅、地道。支持文本直接输入、网页抓取、文件上传等多种方式,并提供多种文本风格和语气选项,满足不同场景的写作需求。\n```",
"将以下技术文档中的一段翻译成更通俗易懂的语言,并添加适当的例子或图示(如果可能),以便非技术背景的读者也能理解:\n```\n当 OpenAI Assistants API 发布时,这标志着 AI 领域向智能体时代迈出了重要一步。它使 OpenAI 从一家提供大型语言模型(LLM)API 的公司,转变为一家提供智能体 API 的企业。\n我认为 OpenAI Assistants API 在多个方面都表现出色,它引入了许多创新且实用的基础设施,专门用于运行智能体应用。然而,这也在某种程度上限制了开发者在其基础上构建真正复杂(且极具价值!)智能体时所能采用的"认知架构"的灵活性。\n这凸显了"智能体基础设施"与"认知架构"之间的本质区别。正如亚马逊创始人杰夫·贝索斯那句经典箴言所言:"专注于让你的啤酒更美味"。\n```",
"用更简洁、更专业、更有说服力的语言改写以下句子,并指出原句存在的问题:\n'由于 DeepSeek-V3 的性能不如那些美国前沿模型——假设在规模曲线上落后约 2 倍,我认为这对于 DeepSeek-V3 来说已经相当慷慨了——这意味着,如果 DeepSeek-V3 的训练成本比美国一年前开发的现有模型低约 8 倍,那将是完全正常、完全符合"趋势"的。我不会给出具体数字,但从前一点可以清楚地看出,即使你完全相信 DeepSeek 宣称的训练成本,他们的表现充其量也只是符合趋势,甚至可能还达不到。例如,这远不如最初的 GPT-4 到 Claude 3.5 Sonnet 的推理价格差异(10 倍),而 3.5 Sonnet 是一款比 GPT-4 更出色的模型。'",
"什么是 AI Agent?它有哪些组成部分?其核心原理是什么?这项技术重要吗?如何开始学习?请结合实际应用场景(如智能客服、自动驾驶、游戏NPC等)进行说明,并推荐一些学习资源。",
"您认为未来五年内,AI Agent 在哪些应用领域最具潜力取得突破性进展?为什么?请分析这些领域的技术现状、市场需求、潜在挑战和发展趋势,并给出您的预测。"
]
# 定义各服务商的配置, 使用 api_key_env 字段
providers = [
{
"name": "火山引擎",
"api_key_env": 'Key_Volces',
"base_url": "https://ark.cn-beijing.volces.com/api/v3",
"model": 'ep-20250217091332-8g29h',
"modelType": "R1"
},
{
"name": "火山引擎",
"api_key_env": 'Key_Volces',
"base_url": "https://ark.cn-beijing.volces.com/api/v3",
"model": "ep-20250217102601-knmvv",
"modelType": "V3"
},
{
"name": "OpenRouter",
"api_key_env": 'Key_OpenRouter',
"base_url": "https://openrouter.ai/api/v1",
"model": 'deepseek/deepseek-r1',
"modelType": "R1"
},
{
"name": "OpenRouter",
"api_key_env": 'Key_OpenRouter',
"base_url": "https://openrouter.ai/api/v1",
"model": "deepseek/deepseek-chat",
"modelType": "V3"
},
{
"name": "DeepSeek官网",
"api_key_env": 'Key_DeepSeek',
"base_url": "https://api.deepseek.com",
"model": 'deepseek-reasoner',
"modelType": "R1"
},
{
"name": "DeepSeek官网",
"api_key_env": 'Key_DeepSeek',
"base_url": "https://api.deepseek.com",
"model": "deepseek-chat",
"modelType": "V3"
},
]
print(f"本次测试开始于中国时间:{datetime.datetime.now(pytz.timezone('Asia/Shanghai')).strftime('%Y-%m-%d %H:%M:%S')}")
# 循环对每个服务商进行测试
for provider in providers:
test_provider(provider, prompts)测试结果
本次测试的完整日志和原始数据已保存在相应的 CSV 文件中。以下是关键性能指标的汇总:
性能指标汇总表
| 模型 | 指标 | 最小值 | 最大值 | 平均值 | TP90 | 成功率 |
|---|---|---|---|---|---|---|
| 火山引擎 R1 | 首字时间 (s) | 0.425 | 1.181 | 0.659 | 1.100 | 100% |
| 生成速度 (tokens/s) | 25.61 | 29.94 | 27.86 | 29.39 | ||
| 火山引擎 V3 | 首字时间 (s) | 0.467 | 1.272 | 0.725 | 1.174 | 100% |
| 生成速度 (tokens/s) | 19.30 | 32.78 | 25.74 | 28.71 | ||
| OpenRouter R1 | 首字时间 (s) | 1.472 | 27.755 | 13.036 | 22.491 | 100% |
| 生成速度 (tokens/s) | 12.62 | 45.44 | 30.38 | 42.88 | ||
| OpenRouter V3 | 首字时间 (s) | 0.765 | 6.037 | 1.513 | 1.464 | 100% |
| 生成速度 (tokens/s) | 4.10 | 19.62 | 7.36 | 9.71 | ||
| DeepSeek R1 | 首字时间 (s) | 8.103 | 8.103 | 8.103 | 8.103 | 8.33% |
| 生成速度 (tokens/s) | 17.27 | 17.27 | 17.27 | 17.27 | ||
| DeepSeek V3 | 首字时间 (s) | 2.199 | 57.081 | 28.498 | 49.700 | 66.67% |
| 生成速度 (tokens/s) | 0.70 | 19.13 | 8.16 | 13.68 |
性能分析
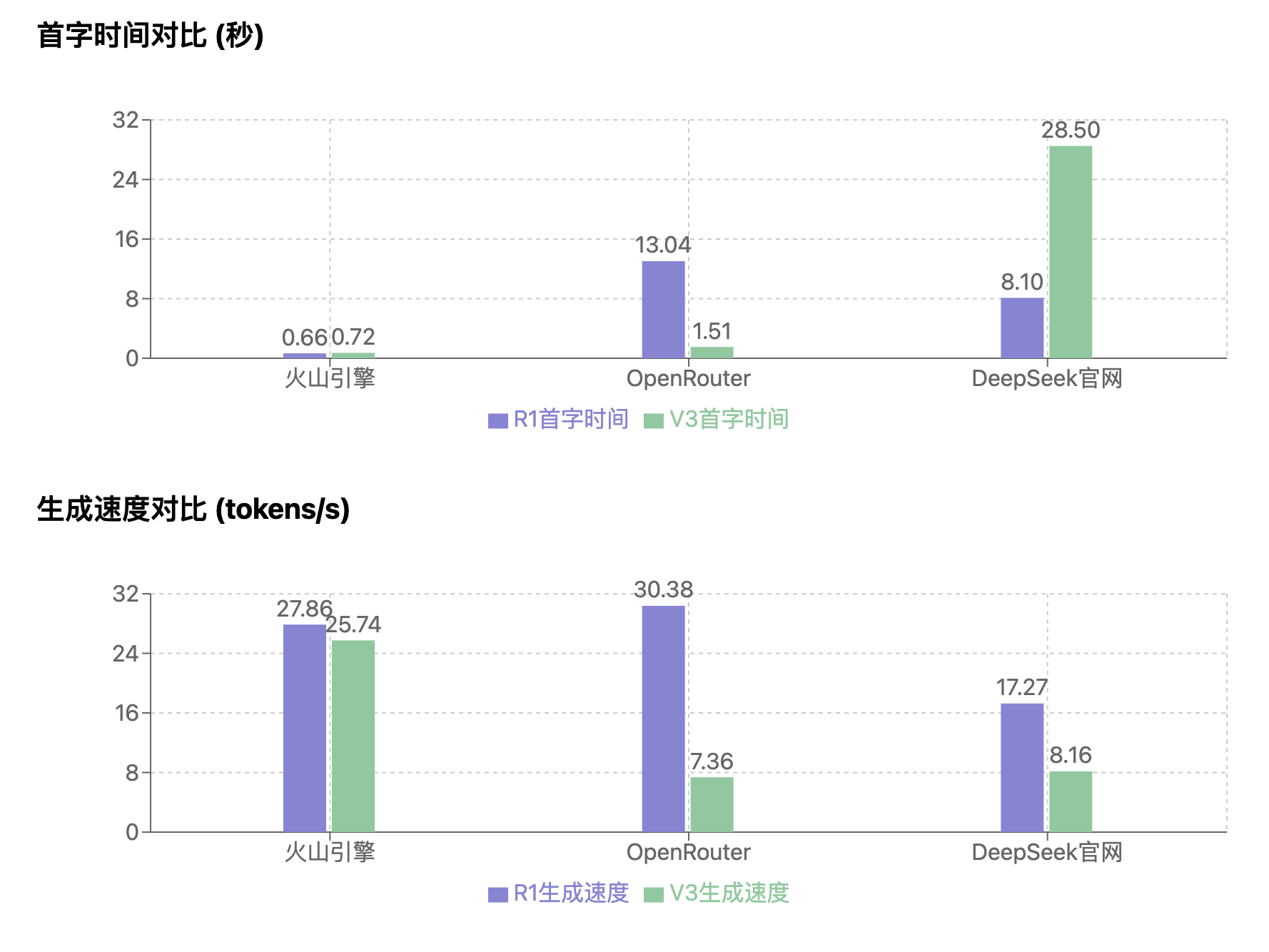
通过对各项指标的综合分析,我们得出以下主要结论:
-
火山引擎全面领先
- 首字响应最快且稳定(平均 0.7 秒左右)
- 生成速度快且稳定(R1:27.86 tokens/s,V3:25.74 tokens/s)
- 成功率 100%,服务稳定性高
- R1 和 V3 两个版本均适合生产环境部署
-
OpenRouter 表现不一
- R1 版本生成速度最高(平均 30.38 tokens/s),但首字时间不稳定(平均 13.036 秒,波动范围 1.472-27.755 秒)
- V3 版本首字时间较好(平均 1.513 秒),但生成速度较低(平均 7.36 tokens/s)
- 两个版本的成功率均为 100%,但性能特点差异较大
-
其他渠道说明
- DeepSeek 官方 API:部分参数未返回,导致脚本执行和统计异常,R1 版本成功率仅 8.33%,V3 版本成功率为 66.67%
- 腾讯云和硅基流动:基础版 TPS 过低,仅适合个人使用和测试场景
- 硅基流动 Pro 版本:可申请更高的 TPS 限额,但本次评测期间申请流程尚未完成,将在后续评测中进行测试
使用建议
基于目前的测试结果,我们建议:
-
生产环境首选火山引擎
- 性能稳定可靠,服务质量有保障
- 根据具体需求选择 R1 或 V3 版本
- 建议建立性能监控机制,定期评估服务质量
-
特定场景可选 OpenRouter R1
- 适用于对生成速度要求高,但对首字响应时间不敏感的场景
- 需要做好容错和重试机制
- 建议进行充分的压力测试
免责声明
本测试结果仅代表特定时间点、特定环境下的性能表现。影响 API 性能的因素众多,且可能随时间变化。建议开发者:
- 结合实际需求进行评估
- 在使用前进行充分测试
- 建立性能监控机制
- 定期进行服务评估
后续计划
本次评测主要关注了 DeepSeek 模型在不同渠道的性能表现。为了提供更全面的参考,我们计划在后续进行以下评测:
-
更多服务商测试
- 包括其他新兴的 DeepSeek 模型服务提供商
- 评测硅基流动 Pro 版本的性能表现
- 对比测试主流大模型服务(如 GPT-4、Claude 等)
-
更深入的性能分析
- 增加成本效益分析
- 测试不同场景下的性能表现
- 评估长期稳定性
-
特定场景测试
- 针对翻译、编程等具体应用场景
- 测试不同语言和任务类型
- 评估特定领域的性能表现
我们将持续关注各服务提供商的更新和改进,适时发布新的评测报告。