LangMem SDK 为 AI Agent 带来了长期记忆功能,告别“金鱼记忆”的时代。这篇译自 LangChain 官方博客的文章,详细介绍了语义记忆、程序记忆和情景记忆三种核心机制,并提供了实用的代码示例。通过阅读本文,您可以了解如何构建具备持续学习、个性化定制以及历史对话记忆能力的 AI Agent。
今日,我们隆重推出 LangMem SDK,旨在帮助智能体(AI Agent)通过长期记忆实现学习和改进。
它提供了一系列工具,用于从对话中提取信息、通过更新提示来优化智能体行为,并维护关于行为、事实和事件的长期记忆。你可以将 LangMem SDK 的核心 API 与任何存储系统和智能体框架结合使用。此外,它还能与 LangGraph 的长期记忆层实现原生集成。我们还推出了一项托管服务,免费提供更强大的长期记忆功能。如果您有兴趣在生产环境中应用,请点击此处 注册。
我们的目标是让 每个人 都能更轻松地构建随时间不断进化、愈加智能和个性化的 AI 体验。这项工作基于我们此前开发的 托管版 LangMem Alpha 服务 以及 LangGraph 的持久化长期记忆层 。
要安装,只需运行:
pip install -U langmem快速链接
关于记忆和自适应智能体
智能体通过记忆进行学习,但记忆的形成、存储、更新和检索方式,直接影响智能体所能学习的内容和执行的任务类型。在 LangChain,我们的经验表明,首先明确智能体需要学习的能力,然后将这些能力映射到特定的记忆类型或方法,最后在智能体中实现这些方法,是一种行之有效的策略。在添加记忆之前,我们认为你应该考虑:
- 应该学习(用户告知)哪些行为,以及预定义哪些行为?
- 应该跟踪哪些类型的知识或事实?
- 应该在什么条件下触发记忆的调用?
虽然可能存在一些重叠,但在构建自适应智能体时,每种记忆类型都具有不同的功能:
| 记忆类型 | 目的 | 智能体应用实例 | 人类类比 | 常见存储形式 |
|---|---|---|---|---|
| 语义记忆 | 事实和知识 | 用户偏好;知识三元组 | 知道 Python 是一种编程语言 | 配置文件或集合 |
| 情节记忆 | 过去的经验 | 少样本示例;过去对话的摘要 | 记住你工作的第一天 | 集合 |
| 程序记忆 | 系统行为 | 核心个性和响应模式 | 知道如何骑自行车 | 提示规则或集合 |
然后重新审视我们上面的问题:
- 应该学习哪些行为,以及固定哪些行为? 你的智能体行为的某些方面可能需要根据反馈和经验进行调整,而其他方面应该保持一致。这将指导你是否需要 程序记忆 来演化行为模式,或者固定的提示规则是否足够。这在精神上类似于 OpenAI 模型规范中的"指挥链"概念,因为学习到的行为是由用户交互塑造的。
- 应该跟踪哪些类型的知识或事实? 不同的用例需要不同类型的知识持久性。你可能需要 语义记忆 来维护关于用户或领域的事实,需要 情景记忆 来从成功的交互中学习,或者两者协同工作。
- 应该在什么条件下触发记忆的调用? 一些记忆(例如核心程序记忆)可能与具体数据无关,它们始终包含在提示之中。有些是数据相关的,可能会根据语义相似性被调用。其他的可能会根据应用程序上下文、相似性、时间等组合来调用。
一个相关的考虑因素是记忆隐私。在 LangMem 中,所有记忆都给出了一个 命名空间。最常见的命名空间将包括一个 use_id,以防止用户记忆的交叉。一般来说,记忆可以限定到特定的应用程序路由、单个用户、跨团队共享,或者智能体可以学习跨所有用户的核心程序。记忆共享的程度由隐私和性能需求决定。
需要注意的是,这与标准 RAG 存在以下几个方面的差异。一个方面是信息的获取方式:通过交互而不是离线数据摄取。另一方面是优先考虑的信息类型。
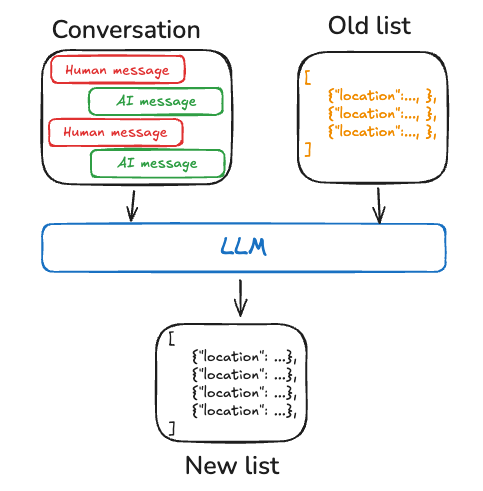
语义记忆:事实
语义记忆存储关键事实(及其关系)和其他信息,这些信息可以作为智能体响应的基础。它可以帮助智能体记住重要的细节。这些细节既没有预先训练到模型中,也无法通过网络搜索或通用检索器获取。
示例代码:
from langmem import create_memory_manager
manager = create_memory_manager(
"anthropic:claude-3-5-sonnet-latest",
instructions="解析用户偏好及事实信息",
enable_inserts=True
)
# 处理对话以提取事实
conversation = [
{"role": "user", "content": "Alice 管理 ML 团队并指导 Bob,Bob 也在该团队中。"}
]
memories = manager.invoke({"messages": conversation})
# 提取和存储新知识
conversation2 = [
{"role": "user", "content": "Bob 现在领导 ML 团队和 NLP 项目。"}
]
update = manager.invoke({"messages": conversation2, "existing": memories})memories = [
ExtractedMemory(
id="27e96a9d-8e53-4031-865e-5ec50c1f7ad5",
content=Memory(
content="Alice 管理 ML 团队并指导 Bob,Bob 也在该团队中。"
),
),
ExtractedMemory(
id="e2f6b646-cdf1-4be1-bb40-0fd91d25d00f",
content=Memory(
content="Bob 现在领导 ML 团队和 NLP 项目。"
),
),
]根据我们的经验,语义记忆是工程师在首次寻求添加记忆层时,要求和想象的最常见的记忆形式(或许在短期对话历史记忆之后)。可以说,它与传统 RAG 系统存在一定的重叠。如果知识可以从另一个存储(文档站点、代码库等)获得,并且如果该存储是事实的来源(而不是交互本身),那么你的智能体可能只需直接检索该知识语料库即可正常工作。或者你可以定期摄取该知识以将其集成到语义记忆系统中。如果知识是关于个性化(关于用户)或在原始材料中找不到的概念关系,那么语义记忆非常适合。
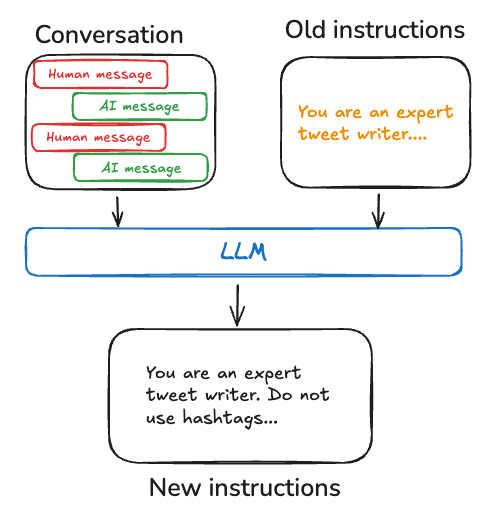
程序记忆:演化的行为
程序记忆是指执行任务的内在知识。对于智能体来说,程序记忆由模型权重、代码和提示共同构成,这些元素共同决定了其功能。在 LangMem 中,我们专注于将学习到的程序保存为智能体提示中更新的指令。
from langmem import create_prompt_optimizer
trajectories = [
(
[
{"role": "user", "content": "告诉我关于火星的信息"},
{"role": "assistant", "content": "火星是第四颗行星..."},
{"role": "user", "content": "我想要更多关于它的卫星的信息"},
],
{"score": 0.5, "comment": "错过了关于卫星的关键信息"}
)
]
optimizer = create_prompt_optimizer(
"anthropic:claude-3-5-sonnet-latest",
kind="metaprompt",
config={"max_reflection_steps": 3}
)
improved_prompt = optimizer.invoke({
"trajectories": trajectories,
"prompt": "你是一位行星科学专家"
})"""
你是一位乐于助人的助手..
如果用户询问关于天文学的问题,请使用真实世界的例子和当前的科学数据清楚地解释主题。
在有帮助时使用视觉参考,并适应用户的知识水平。
平衡实际的观测天文学和理论概念,根据用户需求提供观看建议或技术解释。
"""提示词优化器通过识别成功和不成功交互中的模式,然后更新系统提示以加强有效的行为。这创建了一个反馈循环,其中智能体的核心指令根据观察到的性能而演变。
在我们的 提示词优化工作 的启发下,LangMem 提供了多种用于生成提示词更新建议的算法,包括:metaprompt 使用反思和额外的思考时间来研究对话,然后使用元提示来提出更新;gradient 将工作明确地划分为批判和提示建议的单独步骤,以进一步简化每个步骤的任务;以及一个简单的 prompt_memory 算法,该算法尝试在一个步骤中完成上述操作。
情节记忆:事件和经验
情景记忆(或情节记忆,根据团队内部约定)存储过去交互的记忆。它与程序记忆的不同之处在于它侧重于回忆 特定 经验。它与语义记忆的不同之处在于它侧重于过去事件而不是一般知识,回答智能体如何解决特定问题,而不仅仅是答案是什么。它通常采用少样本示例的形式,每个示例都从较长的原始交互中提取。LangMem 尚未支持用于情景记忆的倾向性实用程序。
立即尝试
查看 文档链接 以获取更多关于如何使用 LangMem 实现自定义记忆系统的示例,包括以下指南:
- 创建一个主动管理自身记忆的 Agent
- 在智能体之间共享记忆
- 使用命名空间记忆以按用户或团队组织信息
- 将 LangMem 集成到你的自定义框架中
如果你的团队希望为智能体赋予个性化或终身学习的能力,欢迎立即填写 兴趣表,开启智能化升级之旅!