在三月份红杉资本举办的AI Ascent 大会上,我谈到了智能体的三个局限性:规划、用户体验和记忆。点击 这里 查看当时的演讲。在这篇文章中,我将更深入地探讨记忆。关于规划的上一篇文章请见 此处,关于用户体验的系列文章请见 此处、此处 和 此处。
如果说 2024 年大语言模型 (LLM) 应用开发领域最火的词汇是"智能体",那么"记忆"可能就是第二火的词汇了。但"记忆"究竟是什么呢?
从宏观层面来看,记忆只是一个用来记住先前交互信息的系统。这对于构建良好的智能体体验至关重要。试想一下,如果你的同事从不记得你告诉过他们的事,以至于你不得不一遍又一遍地重复相同的信息 -- 那将是多么令人沮丧!
人们通常认为大语言模型系统应该天生就具备记忆能力,或许是因为大语言模型已经让人感觉非常像人类了。然而,大语言模型本身并不会固有地记住事情 -- 因此你需要有意识地为其添加记忆功能。但是,究竟应该如何考虑实现这一点呢?
记忆是特定于应用的
我们对记忆问题进行了深入研究,并且我们认为记忆是特定于应用的。
Replit 的编程智能体 和 Unify 的研究智能体,两者选择记住的关于特定用户的信息可能大相径庭。例如,Replit 可能会选择记录用户喜爱的 Python库,而 Unify 则可能着重保存用户所关注公司的行业信息。
正如 之前的一篇文章 中讨论的那样,用户体验 (UX) 是智能体的一个关键方面。不同的用户体验提供了独特的方式来收集反馈并进行更新。
那么,我们在 LangChain 是如何处理记忆问题的呢?
💡 与我们对待智能体的方法非常相似:我们的目标是让用户能够对记忆进行底层控制,并能够根据自己的需要进行定制。
这种理念引导了我们上周在 LangGraph 中推出 Memory Store 时的大部分设计和开发工作。
记忆的类型
虽然你的智能体拥有的记忆 形式 可能因应用而异,但我们确实可以看到一些 常见的 记忆类型。这些记忆类型并不新鲜 -- 它们模仿了 人类的记忆类型。
已经有一些出色的研究将这些人类记忆类型对应到智能体记忆。我最喜欢的是 CoALA 论文。以下是我对每种类型的粗略、通俗易懂的解释,以及当今智能体可能使用和更新这种记忆类型的 实际方法。
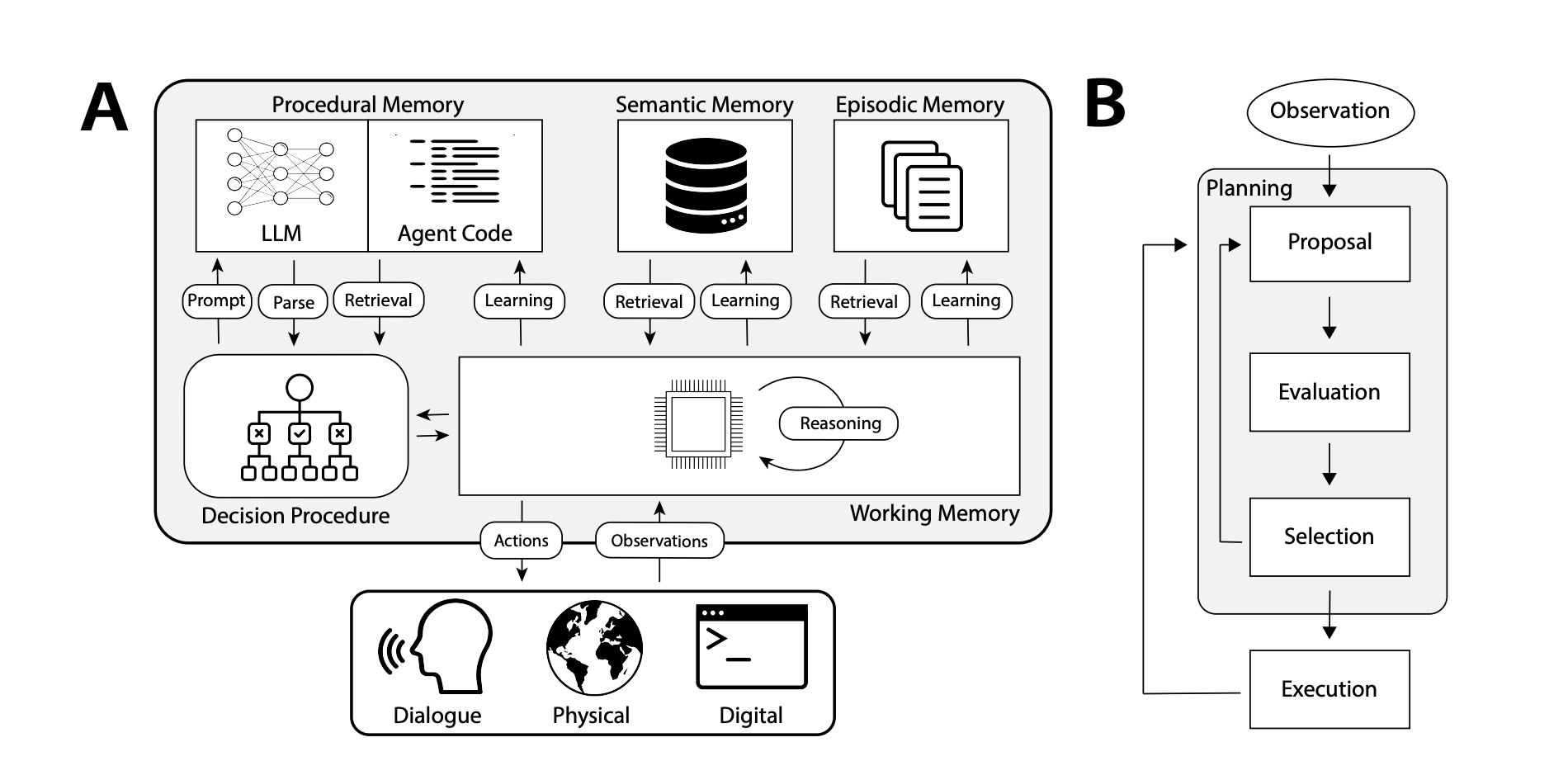
CoALA 论文中的决策程序图(Sumers, Yao, Narasimhan, Griffiths 2024)
程序性记忆 (Procedural Memory)
这个术语指的是长期记忆中关于如何执行任务的部分,类似于大脑的核心指令集。
人类的程序性记忆:记住如何骑自行车。
智能体中的程序性记忆:CoALA 论文将程序性记忆描述为大语言模型权重和智能体代码的结合,从根本上决定了智能体的工作方式。
在实践中,我们几乎没有见到能够自动更新其大语言模型权重或重写代码的智能体系统。然而,我们确实看到一些智能体更新自身系统提示的例子。虽然这是最接近的实际例子,但仍然相对少见。
语义记忆 (Semantic Memory)
这是一个人长期存储的知识库。
人类的语义记忆:它由各种信息片段组成,例如在学校学到的事实、概念的含义以及它们之间的关系。
智能体中的语义记忆:CoALA 论文将语义记忆描述为关于世界的各种事实的存储库。
如今,智能体最常使用语义记忆来实现应用的个性化定制。
在实践中,我们看到这种做法通常是通过使用大语言模型从智能体进行的对话或交互中提取信息来实现的。这些信息的具体形式通常是特定于应用的。然后在未来的对话中检索这些信息,并将其插入到系统提示中,以影响智能体的响应。
情节记忆 (Episodic Memory)
这指的是回想起过去发生的特定事件(亦称情景记忆)。
人类的情节记忆:当一个人回忆起过去经历的特定事件(或"情节")时。
智能体中的情节记忆:CoALA 论文将情节记忆定义为存储智能体过去动作的序列。
情节记忆主要用于确保智能体能够按照预定方式执行任务。
在实践中,情节记忆是通过少样本示例提示来实现的。如果你收集了足够多的这类序列,那么就可以通过动态少样本提示来完成。如果对于之前执行过的特定操作存在 正确 的执行方式,那么这通常非常适合引导智能体。相比之下,如果并非必须存在正确的做事方式,或者如果智能体不断地做新的事情,以至于之前的例子没有太大帮助,那么语义记忆就更相关。
如何更新记忆
除了思考在智能体中更新哪种类型的记忆之外,我们还看到开发者也在思考 更新智能体记忆的方式。
更新智能体记忆的一种方法是 "在热路径中(in the hot path)"。在这种方法中,智能体系统在响应之前显式地决定记住事实(通常通过工具调用)。ChatGPT 就采用了这种方法。
另一种更新记忆的方法是 "在后台(in the background)"。在这种情况下,后台进程在对话期间或之后运行,以更新记忆。
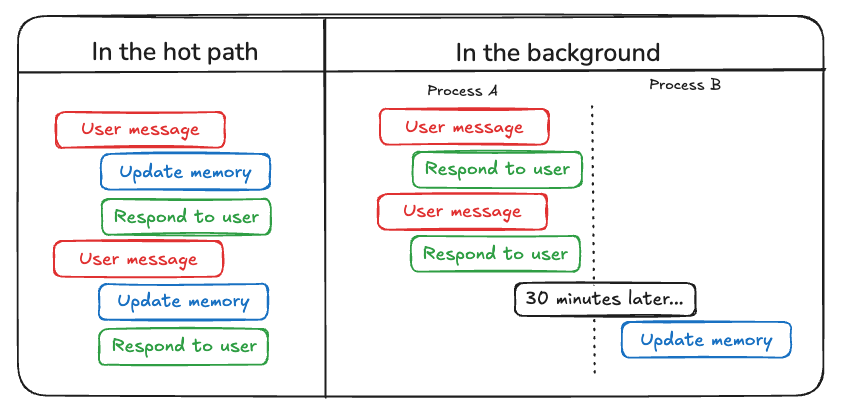
比较这两种方法,"在热路径中"的方法的缺点是会在交付任何响应之前引入一些额外的延迟。它还需要将记忆逻辑与智能体逻辑相结合。
然而,在后台运行避免了这些问题 -- 不会增加延迟,并且记忆逻辑保持独立。但是"在后台"运行也有其自身的缺点:记忆不会立即更新,并且需要额外的逻辑来确定何时启动后台进程。
另一种更新记忆的方法涉及用户反馈,这与情节记忆尤其相关。例如,如果用户将某次交互标记为积极,你可以保存该反馈,供将来参考。
为什么我们关心智能体的记忆?
记忆极大地影响了智能体系统的实用性,因此我们非常有兴趣尽可能轻松地为应用程序利用记忆。
为此,我们在我们的产品中构建了许多与此相关的功能。这包括:
- LangGraph 中 用于记忆存储的底层抽象,使你能够完全控制智能体的记忆
- 用于在 LangGraph 中"在热路径中"和"在后台"运行记忆的 模板
- LangSmith 中用于快速迭代的 动态少样本示例选择
我们甚至构建了 我们自己的一些应用程序 来利用记忆!虽然现在还处于早期阶段,但我们将继续学习关于智能体记忆以及它可以有效应用的领域 🙂
原文地址:Memory for agents
LangChain 智能体系列文章: